La web de Maco048. Criminología
Las mentes simples casi siempre yerran en sus juicios

El test de Rorschach, Google difunde la pseudociencia
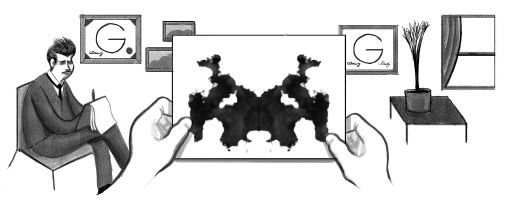
Google conmemoró el aniversario de Hermann Rorschach. Uno de sus trabajos más famosos, el test de Rorschach, es recordado a través de un doodle en el buscador, a pesar de la nula evidencia científica que lo sostiene.
En la página web de Google se ha visto un extraño doodle, que conmemora el 129º aniversario del nacimiento de Hermann Rorschach, el conocido psiquiatra suizo, famoso por desarrollar el test de Rorschach.
Precisamente el dibujo que utiliza Google es la representación de uno de los exámenes de tipo psicodiagnósticos de Hermann Rorschach, que alcanzaron una gran fama en la sociedad en general, ya que trataban de evaluar la personalidad de los individuos.
El test de Hermann Rorschach, así como otro tipo de cuestionarios similares, forman parte del grupo de los instrumentos proyectivos, denominados así por algunas corrientes de la psicología en el pasado. La idea se basa en creer que a través de la diferente interpretación de imágenes, palabras y/u objetos ambiguos, podemos determinar la personalidad de una persona.Este examen carece de validez científica
Del total de exámenes proyectivos existentes, el test de Rorschach es, sin lugar a dudas, el más conocido. Consiste en visualizar diez láminas con diferentes manchas de tinta, para que los individuos expliquen qué ven en ellas. La interpretación de las respuestas, sin embargo, ha tratado de ser estandarizada durante años, algo logrado finalmente por John Exner (Jr.) a través del comprehensive system.
Más allá de la estandarización de la evaluación, no podemos dejar de lado dos criterios fundamentales sobre el test de Hermann Rorschach: ¿tiene validez científica, por un lado, y por otro, puede considerarse fiable? Estas dos cuestiones son importantes, antes de realizar cualquier valoración sobre la comprensión de las respuestas de los individuos.
Una revisión realizada hace tiempo por Scientific American indicaba que los resultados del test de Rorschach eran insuficientes como para determinar la existencia de condiciones como los comportamientos violentos y agresivos, la impulsividad o incluso en la detección de casos de abuso infantil.La personalidad no puede estudiarse a través de diez manchas de tinta
A pesar de que la evidencia científica ha dudado de la validez de este examen, muchos psicólogos lo han usado como prueba rutinaria.
¿Cuáles son los fallos?
Los errores del test de Hermann Rorschach son muy diversos. Por un lado, si analizamos el diseño del propio examen, veremos que no existen grupos control, imprescindibles para diferenciar entre una persona que sufre un determinado trastorno de un individuo que no está afectado. No se realiza ningún examen estadístico de las conclusiones
Además, la validación del test la realiza el propio examen, lo cual nos lleva a pensar en un método bastante poco científico.
La ausencia de variables control, el sesgo experimental y los fallos al no interpretar estadísticamente los resultados obtenidos, son otros de los grandes errores de Hermann Rorschach. En la interpretación tendemos a generalizar las conclusiones en un tema tan complejo como la personalidad de cada persona, que dista mucho de ser igual en todos los individuos.
Por último, en las conclusiones obtenidas tampoco se habla de hipótesis implícitas antes de llevar a cabo el examen, y se ignora por completo el concepto de que los resultados sean o no significativos desde un punto de vista estadístico. ¿Cómo podemos entonces fiarnos del test de Hermann Rorschach si carece de cualquier tipo de validez científica?
Hubiera sido un buen día, por ejemplo, para celebrar Google el aniversario del descubrimiento de los rayos X, y no recordar exámenes psicológicos con nula validez científica, por muy famosos que sean.
Fuente: ALT1040
Angela Bernardo
Licencia CC

![]()
Google declara la guerra a las mafias, la trata y el tráfico de órganos

Google se comprometió recientemente a combatir las mafias, la trata y el tráfico de órganos poniendo la tecnología al servicio de la justicia, en una reunión en Los Ángeles (EE.UU.) entre víctimas del crimen organizado y especialistas que buscan desbaratar las redes ilícitas.
«En un mundo conectado, la gente vulnerable está más a salvo, las víctimas del tráfico pueden conocer sus derechos y hallar oportunidades, los traficantes de órganos pueden ser llevados ante la justicia», dijo Eric Schmidt, presidente de Google, en la cumbre «Redes ilícitas: Fuerzas en Oposición».
La reunión sirvió de escenario para que el cuerpo policial mundial Interpol anunciara el lanzamiento de una aplicación para móviles que permitirá a los usuarios escanear un producto a fin de verificar su autenticidad y ayudar en el combate al contrabando.
Esta aplicación informática ideada por Interpol y desarrollada por Google para el sistema operativo Android es un ejemplo concreto de las formas en que el gigante de internet propone participar en la lucha contra el crimen organizado.
«Desarrollamos esta idea que permitirá al consumidor o a los agentes de la ley, así como a los comercios, escanear un código (a través de su teléfono) y determinar si puede ser verificado o no como auténtico», dijo Ronald Noble, secretario general de la Interpol, durante la reunión de expertos en la localidad de Thousand Oaks, al noroeste de Los Ángeles. El proyecto se llama Registro Mundial de Interpol (IGR, en inglés) y se presenta como «una solución pionera en el combate al tráfico ilícito de productos».
A través de Google Hangout participó además Juan Pablo Escobar, el hijo del fallecido capo de la droga colombiano Pablo Escobar.
«El momento en que tuve más miedo fue cuando comprendí que las autoridades de mi país estaban usando los métodos violentos de mi padre para combatirlo», dijo Escobar. «Y uno no entiende de dónde viene el peligro», añadió.
Fuente: Kioskea.net
![]()
Google presenta una visualización interactiva sobre el comercio mundial de armas
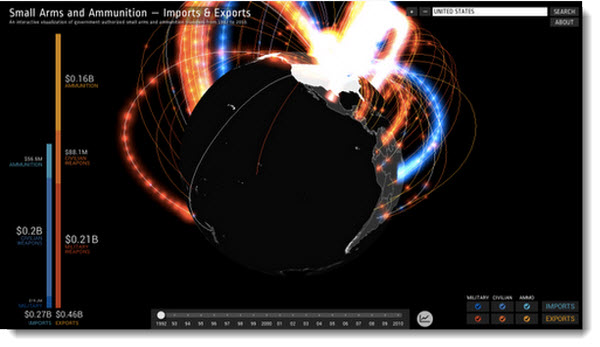
Como parte de esa iniciativa, el equipo de Google han creado en colaboración con el Instituto Igarapé, una cartografía interactiva que nos permite visualizar datos sobre el comercio mundial de armas.
Los datos fueron aportados por PRIO (Peace Research Institute Oslo) con una base de datos de un millón de registros sobre exportaciones e importaciones concernientes a 250 estados, en el lapso de 1992 a 2010. Estos informes corresponden a lo que se clasifica como armas pequeñas y municiones comerciales.
Podemos explorar la aplicación bajo diferentes criterios. Podemos buscar por año, por país, por exportación, importación, entre otros.
Enlace: Mapping Arms Data
Fuente: www.hat’s new
![]()
Datos técnicos curiosos sobre el buscador web de Google
Jeff Dean es uno de los más prestigiosos ingenieros que trabajan en Google, y es una de las personas que mejor conoce la arquitectura del clúster de servidores que tiene su buscador web.
La semana pasada, Dean ha estado en Barcelona en unas conferencias en las que ha hecho públicas algunas cifras bastante llamativas del buscador web de Google y de su funcionamiento, que están resumidas en este post y este post de los blogs personales de dos de los asistentes.
Algunos de estos curiosos datos son:
:: En el periodo 1999-2009 han cambiado:
– el número de consultas en el buscador, que se ha multiplicado por 10.000
– el tiempo entre actualizaciones de un documento web, que se ha reducido 10.000 veces. Antes transcurrían meses hasta que se actualizaba en el índice un sitio web que había sido modificado, y ahora son solamente unos pocos minutos.
– la potencia de procesamiento, que se ha multiplicado por 1.000
– el tiempo de procesamiento de una consulta, que se ha reducido 5 veces. El tiempo medio hace 10 años era de 1 segundo, y ahora tarda unos 200 milisegundos. pagerank
:: Cosas que había a finales de los 90:
– existía un proceso batch que rastreaba las páginas web, y que se detenía cuando había ‘demasiadas’ páginas
– existía un proceso de indexado de estas páginas hecho con herramientas Unix, que era bastante propenso a fallar y a ser contradictorio
– el formato del índice original (año 1997) era un simple sistema ‘byte-aligned’ que codificaba información del campo ‘ocurrencias de una palabra’, lo que suponía un montón de accesos a disco.
:: Al de unos pocos años:
– se redujo un 30% el tamaño del índice, gracias a que se construyo otro de longitud variable basado en bloques que utilizaba tablas para palabras con un gran número de ocurrencias. Además de la reducción del tamaño, el índice era más fácil de decodificar
– se añadieron servidores de cacheo tanto para los resultados como para los ‘snippets’ de los documentos que aparecen en estos resultados
– a principios de 2001 comenzaron a utilizar un índice construido en memoria donde los servidores de indexado (junto a los servidores de documentos, servidores de cacheo, etc.) hablaban directamente con los servidores web donde los usuarios realizan las peticiones
– el índice fue particionado por documentos en lugar de por términos
:: Cosas que se han hecho últimamente:
– se utiliza tecnología contruida dentro de Google. Tanto la física (el diseño de los racks, las placas madre) como la lógica (modifica el kernel de Linux, sistema ‘Google File System‘, sistema ‘BigTable‘)
– se utiliza el entorno de desarrollo MapReduce para indexar
– en 2004 se comenzó a utilizar a un sistema jerárquico para servir los índices, y que estaba basado en índices constuidos sobre ‘Google File System’
– actualizaciones del índice mucho más rápidas
– en 2007 se añadió el servidor ‘super root’ que comunica con todos los servidores de índices (Google News, buscador de imágenes, buscador de vídeos) para permitir ‘Google Universal Search‘
:: Pasos que Google sigue para experimentar con cambios en los algoritmos del buscador:
– se gesta una idea de nuevo ránking
– se generan datos para ejecutar pruebas rápidamente utilizando MapReduce, BigTable, etc.
– se realizan pruebas de los resultados tanto con humanos como con consultas aleatorias para comprobar los cambios en el ránking.
– se experimenta este cambio con un pequeño porcentaje de las búsquedas reales (por eso a veces los usuarios vemos experimentos)
– se realizan ajustes sobre la implementación para pre-procesar los datos y hacerlos factibles a plena carga, incorporando a su vez la información necesaria al índice
:: Futuros retos:
– manejo de información en diferentes idiomas. Actualmente hay una funcionalidad parecida, pero se pretende mejorarlo en muchos aspectos
– desarrollo de sistema capaz de mostrar en los resultados documentos tanto públicos (rastreados de la WWW), como privados (por ejemplo, archivos de ‘Google Docs‘) o semi-privados (compartidos).
– construcción automática de sistemas de tratamiento de la información para diferentes necesidades.
Fuente: google.dirson.com

