Actualidad informática
Noticias y novedades sobre informática
¿Google está a punto de construir el primer qubit del mundo?

El qubit es la unidad básica de computación cuántica. Así que a los desarrolladores de hardware cuántico obviamente les gusta presumir de cuántos tienen. Aunque algunos afirman tener miles en sus dispositivos, hay un sentimiento muy real de que nadie ha construido ni siquiera uno solo.
Hay un par de cosas diferentes para las que usamos el nombre del qubit. Uno es un qubit físico. La parte física se refiere al hecho de que estos son objetos reales de la vida real. La parte de bits nos dice que estos objetos deberían tener dos posibles estados. Y lo que es para el cuántico, ya que necesitamos manipular los estados de una manera cuántica mecánica.
Cualquier qubit que merezca el nombre también debe tener un ruido extremadamente bajo. La forma en que los manipulamos e interactuamos debería ser casi perfecta. Como un logro de la física experimental, deben estar en la cúspide: Una maravilla de la ciencia y la ingeniería. Aun así, no son suficientemente buenos. Para las ordenadores cuánticos, casi perfecto es casi inútil.
Esto no es más de lo que esperamos de los ordenadores normales. Hay millones de píxeles en tu pantalla, pero te darías cuenta si sólo uno estuviera haciendo algo al azar. Lo mismo es cierto para todos los millones de bits que nadan alrededor en sus programas. Sólo se necesita un valor de conmutación de unos pocos porque están aburridos para que todo se convierta en un sinsentido.
Cuando programamos, a menudo olvidamos que los bits de nuestro ordenador tienen una forma corpórea real. Pensamos en ellos como un concepto abstracto, puro e incorruptible. De lo contrario, el desarrollo de software sería una actividad muy diferente. Los programas cuánticos están diseñados con el mismo grado de perfección en mente. Para ejecutarlos, necesitamos renuncias lógicas: encarnaciones de la idea misma de la información cuántica.
Construir qubits lógicos requiere que domemos la naturaleza de sus primos físicos. Necesitamos corrección de errores cuánticos. Muchas de las partes físicas son reunidas y conducidas a ser más grandes que la suma de sus partes. Cuanto más qubits físicos usemos, mejor será el efecto. El ruido disminuye exponencialmente, hasta que podemos estar seguros de que no ocurrirá ni un solo error durante el cálculo.
Esto no está exento de costes. No debemos pensar en gastar unos pocos cientos de qubits físicos para construir uno solo lógico. Pero si esto significa alcanzar la promesa completa de computación cuántica, valdrá la pena.
El diseño más popular para la corrección de errores cuánticos es el código de superficie. Para el código de superficie más pequeño, se necesitan 17 qubits físicos. Éstos construirían un qubit lógico, pero no con la suficiente complejidad como para hacer algo con él.
Todavía no se ha logrado nada parecido. Para ver por qué, echemos un vistazo a lo que se necesitaría.
Esto es un código de superficie. Los 17 puntos, tanto blancos como negros, son los qubits físicos. Las 24 líneas coloreadas representan un cierto tipo de operación cuántica, la controlada-NO. Para cada par de salidas conectadas, esta operación debería ser posible realizarla de forma limpia y directa.
El principal desafío es conectar todos estos controles-NO. Tener 17 qubits en nuestro procesador cuántico no es suficiente. También necesitamos el conjunto de instrucciones para soportar esta red específica de procesos.
Tener un montón de qubits físicos en una línea son noticias viejas, dos líneas al lado de la otra también es factible. Pero la red 2D de conexiones necesarias para el código de superficie es mucho más difícil.
Aun así, Google promete esto y mucho más para finales de año. Prometieron una red de 7×7 de 49 qubits físicos. Esto sería un gran paso adelante en comparación con otros dispositivos, como la celosía IBM 2×8 de 16 qubits físicos.
El dispositivo IBM tiene suficiente conectividad para hacer un bit lógico a partir de qubits físicos. En los próximos meses harán cosas mucho más geniales, como es de esperar del dispositivo a la vanguardia de su campo. Pero hacer un qubit lógico no será uno de sus logros.
El hecho de que los 49 qubits de Google serán tan revolucionarios hace difícil creer que lo veremos antes de que acabe el año. Los hitos más realistas para este año son un dispositivo de 17 qubit de IBM, y uno de 20 qubit de Google. Ambos tienen suficientes qubits para empezar con el código de superficie. Pero, ¿tienen el diseño correcto? Sólo el tiempo lo dirá.
Quizá no tengamos que esperar mucho tiempo. John Martinis, el encargado de construir los dispositivos cuánticos de Google, dará una charla la próxima semana. El título…
Escalado de errores lógicos de medición con el código de superficie
Los códigos de superficie están en el radar de los gigantes tecnológicos. El primer qubit lógico del mundo se acerca. ¿Ya lo ha gestionado el dispositivo de 20 qubit de Google?
Ampliar en: HACKERMOON
![]()

DeepL instruye a otros traductores en línea con aprendizaje automático inteligente

Los gigantes tecnológicos Google, Microsoft y Facebook están aplicando las lecciones de aprendizaje automático (machine learning) a la traducción, pero una pequeña empresa llamada DeepL las ha superado a todas y ha elevado el listón en este campo. Su herramienta de traducción es tan rápida como la competencia, pero más precisa y matizada que cualquiera de las que se conocen.
Mientras que Google Translate a menudo busca una traducción muy literal que no tiene en cuenta algunos matices y expresiones idiomáticas (o que la traducción de estas expresiones idiomáticas es un error), DeepL a menudo proporciona una traducción más natural que se acerca más a la de un traductor capacitado.
Algunas pruebas de mi propia experiencia con alguna literatura francesa que conozco lo suficientemente bien como para juzgar que DeepL gana habitualmente. Menos errores de tensión, intención y concordancia, además de una mejor comprensión y despliegue del lenguaje hacen que la traducción sea mucho más legible. Nosotros pensamos que sí, y también los traductores en las pruebas ciegas de DeepL.
Si bien es cierto que el significado puede transmitirse con éxito a pesar de los errores, como lo demuestra la utilidad que todos hemos encontrado en las traducciones automáticas más pobres, está lejos de garantizar que cualquier traducción valga.
Linguee evolucionado
DeepL nació de Linguee, una herramienta de traducción que existe desde hace años y, aunque popular, nunca llegó a alcanzar el nivel de Google Translate, esta última tiene una enorme ventaja en marca y posición. El cofundador de Linguee, Gereon Frahling, solía trabajar para Google Research, pero en 2007 abandonó la empresa para dedicarse a esta nueva empresa.
El equipo ha estado trabajando con el aprendizaje automático durante años, para tareas adyacentes a la traducción principal, pero fue sólo el año pasado que comenzaron a trabajar en serio en un sistema y una empresa completamente nuevos, que llevarían el nombre de DeepL.
Frahling dijo que había llegado el momento:»Hemos construido una red de traducción neuronal que incorpora la mayoría de los últimos desarrollos, a los que hemos añadido nuestras propias ideas».
Una enorme base de datos de más de mil millones de traducciones y consultas, además de un método de traducción mediante la búsqueda de fragmentos similares en la web, sirvió para una base sólida en el entrenamiento del nuevo modelo. También armaron lo que dicen que es el 23º superordenador más poderoso del mundo, convenientemente ubicado en Islandia.
Los desarrollos publicados por universidades, agencias de investigación y competidores de Lingueee demostraron que las redes neuronales convolucionales eran el camino a seguir, en lugar de las redes neuronales recurrentes que la empresa había estado utilizando anteriormente. Este no es realmente el lugar para entrar en las diferencias entre las CNNs y las RNNs, por lo que debe ser suficiente decir que para una traducción precisa de largas y complejas cadenas de palabras relacionadas, la primera es una mejor opción siempre y cuando se pueda controlar sus debilidades.
Por ejemplo, de una CNN podría se puede decir que aborda una palabra de la oración a la vez. Esto se convierte en un problema cuando, por ejemplo, como sucede comúnmente, una palabra al final de la oración determina cómo debe formarse una palabra al principio de la oración. Es un desperdicio repasar toda la oración sólo para encontrar que la primera palabra que la red escogida está equivocada, y luego empezar de nuevo con ese conocimiento, así que DeepL y otros en el campo de aprendizaje automático aplican «mecanismos de atención» que monitorean esos posibles tropiezos y los resuelven antes de que la CNN pase a la siguiente palabra o frase.
Hay otras técnicas secretas en juego, por supuesto, y su resultado es una herramienta de traducción que personalmente usaré por fefecto. Espero con impaciencia ver a los demás mejorar su juego.
![]()
Google Transformer resuelve un problema complicado en la traducción automática
El aprendizaje automático ha resultado ser una herramienta muy útil para la traducción, pero tiene algunos puntos débiles. La tendencia de los modelos de traducción a hacer su trabajo palabra por palabra es una de ellas, y puede llevar a errores graves. Google detalla la naturaleza de este problema, y su solución, en un interesante post en su blog de Investigación.
El problema se explica bien por Jakob Uszkoreit, del departamento de procesamiento del lenguaje natural de la empresa. Considere las dos oraciones siguientes:
Llegué al banco después de cruzar la calle.
Llegué al banco después de cruzar el río.
Obviamente,»banco» significa algo diferente en cada oración, pero un algoritmo que mastica su camino podría fácilmente escoger el equivocado, ya que no sabe qué «banco» es el correcto hasta que llega al final de la oración. Esta clase de ambigüedad está en todas partes una vez que empiezas a buscarla.
Yo, yo sólo reescribiría la oración (Strunk and White advirtió sobre esto), pero por supuesto que no es una opción para un sistema de traducción. Y sería muy ineficaz modificar las redes neuronales para traducir básicamente toda la oración y ver si está pasando algo raro, y luego intentarlo de nuevo si lo hay.
La solución de Google es lo que se llama un mecanismo de atención, integrado en un sistema que llama Transformer. Compara cada palabra con cada palabra de la oración para ver si alguna de ellas afectará la una a la otra de alguna manera clave – para ver si «él» o «ella» está hablando, por ejemplo, o si una palabra como «banco» significa algo en particular.
Cuando la oración traducida está siendo construida, el mecanismo de atención compara cada palabra como se agrega a cada otra. Este gif ilustra todo el proceso. Bueno, más o menos.

Una empresa de traducción competidora de Google, DeepL, también utiliza un mecanismo de atención. Su co-fundador citó este problema como uno en el que también habían trabajado duro, e incluso mencionó queestá basado en el artículo de Google (atención es todo lo que necesitas), aunque obviamente hicieron su propia versión. Y una muy efectiva, quizás incluso mejor que la de Google.
Un efecto secundario interesante del enfoque de Google es que da una ventana a la lógica del sistema: porque Transformer le da a cada palabra una puntuación en relación con cada otra palabra, se puede ver qué palabras «piensa» que están relacionadas, o potencialmente relacionadas:

Este es otro tipo de ambigüedad, donde «él» podría referirse a la calle o al animal, y sólo la última palabra lo delata. Lo resolveríamos automáticamente, pero las máquinas deben ser enseñadas.
![]()
El manifiesto de Google no es sexista o anti-diversidad. Es ciencia

Damore dijo que la brecha de género en la diversidad de Google no se debía a la discriminación, sino a diferencias inherentes en lo que los hombres y las mujeres consideran interesante. Danielle Brown, nueva vicepresidenta de Google para la diversidad, integridad y gobernabilidad, acusó al manifiesto de avanzar «suposiciones incorrectas sobre género», y Damore confirmó anoche que fue despedido por «perpetuar los estereotipos de género».
A pesar de cómo se ha valorado, el memorándum era justo y factualmente exacto. Los estudios científicos han confirmado las diferencias sexuales en el cerebro que conducen a diferencias en nuestros intereses y comportamiento.
Como se menciona en el memorándum, los intereses de género se predicen por la exposición a la testosterona prenatal – niveles más altos se asocian con una preferencia por las cosas mecánicamente interesantes y las ocupaciones en la edad adulta. Los niveles más bajos se asocian con una preferencia por las actividades y ocupaciones orientadas a las personas.Esta es la razón por la cual los campos STEM (ciencia, tecnología, ingeniería y matemáticas) tienden a ser mayoritariamente ocupados por los hombres.
Se ven pruebas de esto en las niñas con una condición genética llamada hiperplasia suprarrenal congénita, que están expuestas a niveles inusualmente altos de testosterona en el útero. Cuando nacen, estas niñas prefieren los juguetes con ruedas, como los camiones, incluso si sus padres ofrecen más retroalimentación positiva cuando juegan con juguetes típicos femeninos, como muñecas. Del mismo modo, los hombres que están interesados en las actividades típicas de la mujer, probablemente estuvieron expuestos a niveles más bajos de testosterona.
Además, nuevas investigaciones en el campo de la genética demuestran que la testosterona altera la programación de células madre neurales, lo que lleva a las diferencias sexuales en el cerebro, incluso antes de que termine de desarrollarse en el útero. Esto sugiere además que nuestros intereses están fuertemente influenciados por la biología, en oposición a ser aprendidos o socialmente construidos.
Muchas personas, entre ellas el ex empleado de Google, han intentado refutar los puntos del memorandum, alegando que contradicen las últimas investigaciones.
Me encantaría saber qué «investigación hecha […] durante décadas» se refiere, porque miles de estudios sugieren lo contrario. Un solo estudio, publicado en 2015, afirmó que los cerebros masculinos y femeninos existían a lo largo de un «mosaico» y que no es posible diferenciarlos por sexo, pero esto ha sido refutado por cuatro – sí, cuatro – estudios académicos desde entonces.
Esto incluye un estudio que analizó exactamente los mismos datos del cerebro del estudio original y encontró que el sexo de un cerebro determinado podría ser correctamente identificado con un 69 a 77 por ciento de precisión.
Por supuesto, las diferencias existen a nivel individual, y esto no significa que el medio ambiente no juega ningún papel en nuestra formación. Pero afirmar que no hay diferencias entre los sexos cuando se miran los promedios grupales, o que la cultura tiene mayor influencia que la biología, simplemente no es cierto.
De hecho, la investigación ha demostrado que las culturas con mayor equidad de género tienen mayores diferencias sexuales en lo que respecta a las preferencias de trabajo, porque en estas sociedades, las personas son libres de elegir sus ocupaciones en función de lo que disfrutan.
Como sugiere el memorandum, no es realista tratar de cumplir una cuota de 50 por ciento de mujeres en STEM. A medida que la equidad de género continúa mejorando en las sociedades en desarrollo, debemos esperar que esta brecha de género se amplíe.
Esta tendencia continúa en el área de la personalidad, también. Contrariamente a lo que los detractores le harían creer, las mujeres tienen, en promedio, un nivel más alto en neuroticismo y ser agradables, y menor tolerancia al estrés.
Algunos intencionalmente niegan la ciencia porque temen que se utilice para justificar el mantenimiento de las mujeres de STEM. Pero el sexismo no es el resultado de conocer hechos. Es el resultado de lo que la gente elige hacer con ellos. Esto es exactamente lo que la muchedumbre de indignación debe movilizarse para, en lugar de negar la realidad biológica y estar contento de pasar un fin de semana doxxing un hombre para que él perdería su trabajo. En este punto, como se anunció en el manifiesto de Damore, deberíamos estar más preocupados por la diversidad de puntos de vista que la diversidad que gira alrededor del género.
Ampliar en: The Globe and Mail
![]()
Ordenador cuántico de Google

Aquí es donde el concepto de «supremacía cuántica» – será capaz de demostrar de manera concluyente la capacidad de realizar un cálculo que una computadora clásica no puede – entra en juego. Para comprobar la validez de tal cálculo, se requerirían los mejores supercomputadores de hoy, y de acuerdo con Martinis, lo más que podrían competir con una computadora cuántica de 50 qubit – más qubits y un supercomputador no serán suficientes. A pesar de eso, Martinis me dice que al entrar en «la era de un montón de qubit», utilizando la supremacía cuántica como una herramienta de evaluación comparativa para ver qué tan bien funciona su sistema es crucial. Para su actual simulador de 9 qubit, «la supremacía nos dio datos muy valiosos y tenemos algoritmos extremadamente precisos para ello», dice.
Aparte de eso, el equipo de Google también está trabajando duro para predecir y corregir los posibles problemas de hardware que puedan surgir a medida que aumentan el número de qubits, cada uno de los cuales debe ser «muy bueno y coherente». Esto incluye algunos requisitos específicos de ingeniería del sistema . Para diseñar mejores procesadores de computación cuántica, el equipo de Martinis contrató a la compañía canadiense Anyon Systems. Por suerte, el director general de la empresa, Alireza Najafi-Yazdi, también estuvo en la reunión de marzo e incluso dio una conferencia de prensa. Najafi-Yazdi, un ingeniero de formación, cofundó la puesta en marcha en 2014 para desarrollar sistemas de software y simulación que ayudan a diseñar y optimizar la electrónica cuántica y otros dispositivos a nanoescala en los que los efectos cuánticos entran en juego.
Anyon Systems se especializa en el desarrollo de herramientas computacionales y simulaciones «masivamente paralelas», utilizando supercomputadoras para ayudar a diseñar el hardware para futuras computadoras cuánticas. La compañía actualmente está colaborando con el equipo de Martinis para «usar el software de simulación de Anyon Systems para predecir la conversación cruzada entre los diferentes componentes de un procesador cuántico de 6 bits», explica Najafi-Yazdi, agregando que «una comparación entre las mediciones experimentales y los resultados numéricos muestran Excelentes acuerdos que demuestran la promesa de herramientas paralelas masivas en la ingeniería de nuevos procesadores cuánticos «. Añadió que algunas simulaciones ya habían revelado posibles problemas con el chip superconductor que podría ser abordado durante la simulación, en lugar de pasar meses construyendo el dispositivo sólo para encontrarlo No funciona como se esperaba.
Antes de que Martinis y yo nos separáramos después de nuestra charla rápida, mencionó que tanto se discute en estas sesiones que todo su equipo se reúne cada noche para discutir ideas, dice que el equipo está realmente trabajando para llegar a 20 qubits muy pronto. «Todo depende de cómo van nuestras soluciones finales. El objetivo de Google es que nuestro equipo de 50 qubit esté listo para finales de este año. Puede suceder, pero estoy más centrado en perfeccionar el chip de 20 qubit ahora. «En cualquier caso, Martinis confía en que su 50-qubit no está tan lejos y es sólo una cuestión de tiempo antes de que tengan un funcionamiento y relativamente libre de errores de la computadora cuántica en su mira … momentos emocionantes de hecho.
Ampliar en: IOP
![]()
CWI y Google anuncian la primera colisión para el estándar de seguridad industrial SHA-1
Investigadores del instituto de investigación holandés CWI y Google anunciaron conjuntamente que han roto en la práctica el estándar de seguridad de Internet SHA-1. Este estándar industrial se utiliza para firmas digitales y verificación de integridad de archivos, que protegen transacciones de tarjetas de crédito, documentos electrónicos, repositorios de software de código abierto GIT y distribución de software. El cryptanalista de CWI Marc Stevens dice: «Muchas aplicaciones todavía utilizan SHA-1, aunque fue oficialmente desaprobado por NIST en 2011 después de debilidades expuestas desde 2005. Nuestro resultado demuestra que su abandono por una gran parte de la industria ha sido demasiado lento y que la migración a normas más seguras debería darse lo antes posible «.
El esfuerzo conjunto dirigido por Marc Stevens (CWI) y Elie Bursztein (Google) comenzó hace más de dos años para realizar la investigación avanzada de criptoanalítica de Stevens en la práctica con la infraestructura de computación de Google. Ahora lograron romper con éxito el estándar de la industria SHA-1 usando un llamado ataque de colisión. SHA-1, es un algoritmo criptográfico diseñado por la NSA y que fue estandarizado por NIST en 1995 para computar de forma segura las huellas dactilares de los mensajes. Estas huellas dactilares se utilizan en el cómputo de firmas digitales, que son fundamentales para la seguridad en internet, como la seguridad HTTPS (TLS, SSL), banca electrónica, firma de documentos y software. Las colisiones – diferentes mensajes con la misma huella digital – pueden conducir a falsificaciones de firmas digitales. Por ejemplo, una firma SHA-1 obtenida para un archivo también puede ser mal utilizada como una firma válida para cualquier otro archivo colisionado.
La colisión SHA-1 anunciada es la culminación de una línea de investigación iniciada en el CWI hace más de siete años para desarrollar un ataque práctico óptimo de colisión contra SHA-1. Esto dio lugar previamente al ataque teórico actualmente mejor conocido de Stevens en 2012 en el cual el resultado anunciado se ha construido más adelante. Elie Bursztein dice: «Encontrar la colisión en la práctica llevó un gran esfuerzo tanto en la construcción del ataque criptoanalítico y en su ejecución a gran escala.Requería más de 9.223.372.036.854.775.808 cálculos SHA1 que lgastaría 6500 años de cálculo de la CPU y 100 años de computación GPU. Es más de 100000 veces más rápido que un ataque de fuerza bruta.Usamos la misma infraestructura que potencian muchos proyectos de Google AI, incluyendo Alpha Go y Google Photo, así como Google Cloud «.
Stevens dice: «Las lecciones deberían haberse aprendido de las advertencias sobre ataques similares contra el predecesor MD5 de SHA-1, como la creación de una Autoridad de Certificación deshonesta en 2009 por un equipo internacional del que formé parte y un ataque de los estados nacionales en 2012 para elaborar actualizaciones maliciosas de Windows para infectar las máquinas de destino en el Oriente Medio para el espionaje, que demostré ser una variante de ataque criptográfico desconocido». En el otoño de 2015, Stevens, junto con dos coautores, advirtió que encontrar una colisión SHA-1 podría costar alrededor de $ 75K- $ 120K mediante la explotación de recursos de bajo costo GPU en Amazon EC2, que era significativamente más barato de lo esperado anteriormente.
La colisión del equipo se utiliza para crear dos archivos PDF diferentes con la misma huella daigital SHA-1, pero eligió contenidos visibles distintos, por ejemplo dos contratos con honorarios financieros sustancialmente diferentes. Después del proceso de divulgación responsable, el equipo esperará 90 días antes de lanzar un generador de PDF que permitirá a cualquier persona crear pares de documentos PDF parecidos a su elección usando la colisión del equipo.
Para ayudar a prevenir el uso indebido de dichos documentos PDF falsos, el equipo ofrece una herramienta gratuita en línea para buscar colisiones SHA-1 en documentos, que se basa en la técnica de contra-criptoanálisis de Stevens 2013 para detectar si se ha creado un solo archivo con un Ataque de colisión cryptanalítica. Se puede encontrar en: shatterered.io . La misma protección para los documentos PDF es ahora automática para los usuarios de Gmail y Google Drive. Para defenderse contra ataques de colisión SHA-1 los sistemas deben migrar a SHA-2 o SHA-3. En el caso de HTTPS, el esfuerzo para pasar de certificados SHA-1 a certificados SHA-2 comenzó en 2015. Y a partir de este año los navegadores marcarán los certificados basados ??en SHA-1 como inseguros. De forma similar, los sistemas de respaldo y los sistemas de firmas de documentos deben pasar a SHA-2.
Este resultado es fruto de una colaboración a largo plazo entre el Grupo de Criptología de Centrum Wiskunde & Informatica, el instituto nacional de investigación para las matemáticas y la informática en los Países Bajos, y el Grupo de Seguridad de Investigación, Privacidad y Anti-abuso de Google. Hace dos años Marc Stevens y Elie Bursztein, líder del equipo de investigación anti-abuso de Google, comenzaron a colaborar en hacer criptoanalíticas de Marc ataques contra SHA-1 práctica usando la infraestructura de Google. Desde entonces, muchos investigadores de CWI y Googlers han ayudado a hacer posible este proyecto, incluyendo a Pierre Karpman (CWI) que trabajó en el cryptanalísis y la implementación de prototipos de GPU, y de Google Ange Albertini que desarrolló el ataque PDF, Yarik Markov que se encargó de la GPU distribuida Código y Clement Blaisse que supervisaron la confiabilidad de los cálculos.
Más detalles sobre el ataque SHA1, cómo detectarla y el trabajo de investigación que detalla el ataque está disponible en https://shattered.io .
![]()
Chromebit, el ordenador de Google de solo 75 gramos
 Ya está a la venta en EE.UU., por 85 $ Chromebit, ordenador con forma de barra que puede conectarse a la interface HDMI de cualquier monitor para que tengamos un ordenador .
Ya está a la venta en EE.UU., por 85 $ Chromebit, ordenador con forma de barra que puede conectarse a la interface HDMI de cualquier monitor para que tengamos un ordenador .
La idea de Chromebit es sencilla: cuenta con 16 GB de espacio, procesador Rockchip RK3288 a 1,8 GHz y 2 GB de memoria RAM, cuando lo conectamos a un monitor veremos un ordenador con el sistema operativo Chrome OS, permitiendo así navegar por internet, visualizar Netflix, usar aplicaciones de Google y miles de opciones existentes en la web, recordando que con Chrome OS no instalamos aplicaciones en el ordenador y sí las usamos directamente online.
Cuenta con Bluetooth, que permite conectar ratón y teclado, así como una interface USB, que también podremos usar para dicha finalidad.
![]()
Los servidores de Google mueven un petabit por segundo

Google dejó de trabajar con productos de compañías como Cisco y en 2004 decidió crear sus propios servidores y su propia red que cumpliese con todos sus requisitos. Porque hay veces en las que si quieres que algo salga bien tienes que hacerlo tú mismo.
El resultado fue Jupiter, la red de servidores de Google compuesta por 100000 sistemas que supone una gran ventaja frente a la competencia como Microsoft y Amazon; no sólo sirve para sus propios productos sino también para vender servicios en la nube a otras compañías.
Es capaz de mover un petabit por segundo en total (1000000 Gb por segundo). En términos reales eso significa que los 100000 servidores de la red se comunican entre ellos de manera arbitraria a una velocidad de 10 Gb/s.
Fuente: Google Research Blog
![]()
Evolución del uso de los navegadores de internet
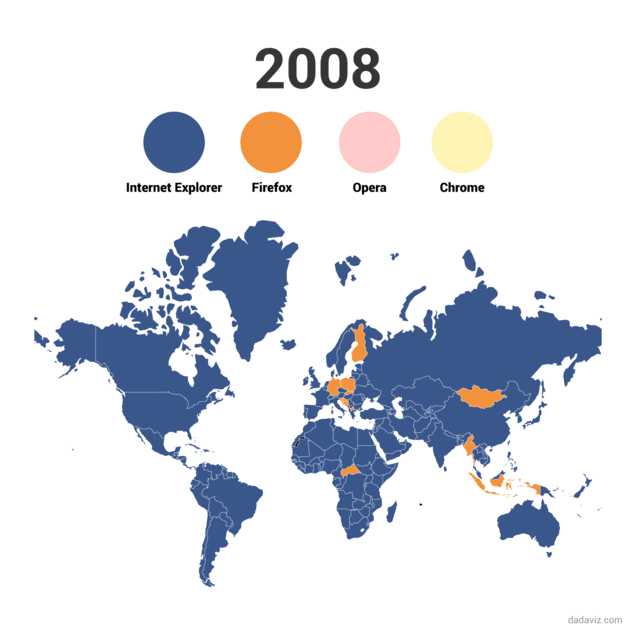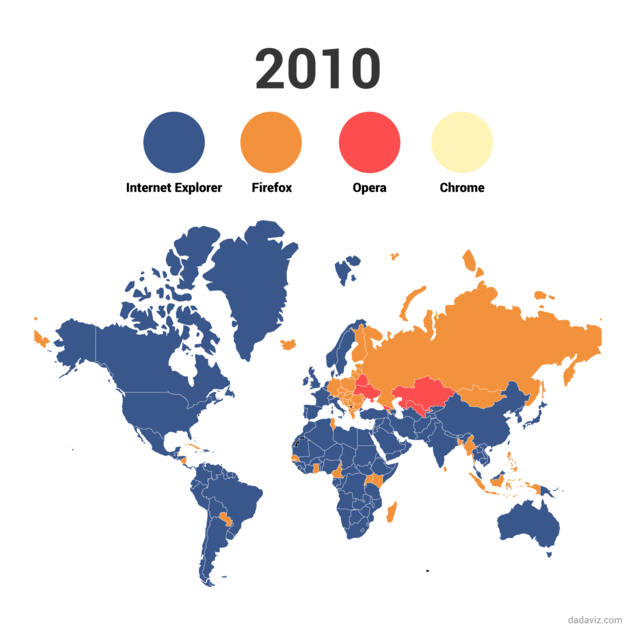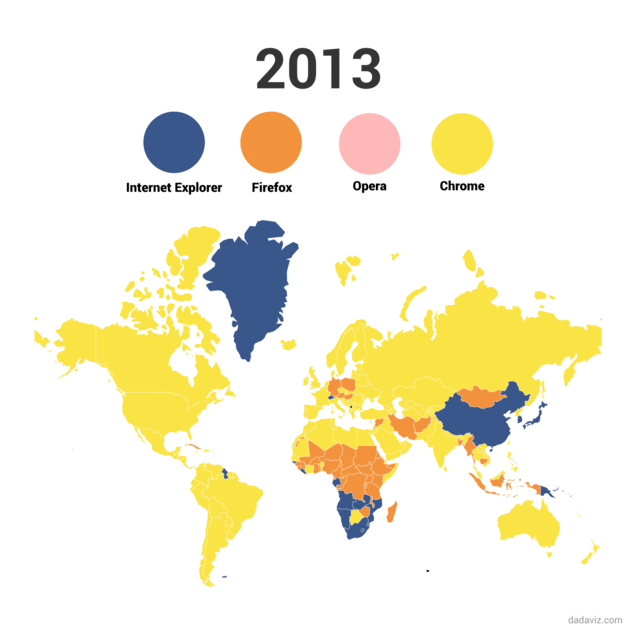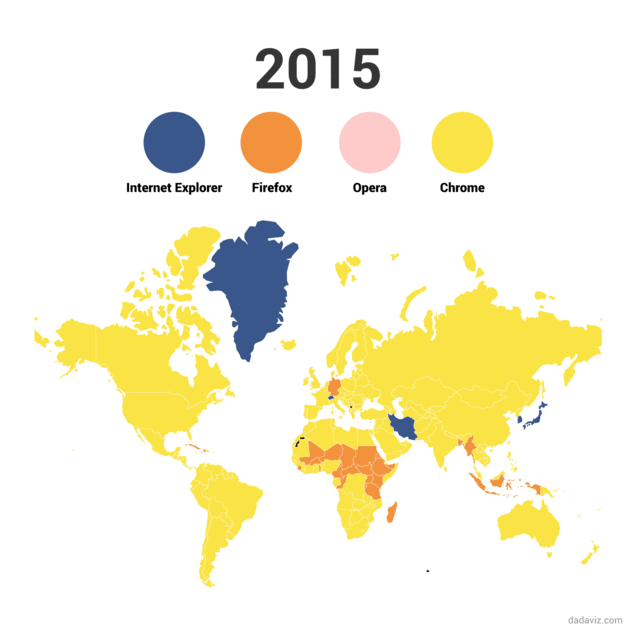
El navegador Chroome, de Google, Se lanzó el dos de septiembre de 2008. Comenzó un ascenso imparable hasta convertirse, según algunas webs de medición como Statcounter en el navegador más utilizado del mundo con más de un 50% de cuota de mercado. Este gráfico animado, desarrollado por Dadaviz, permite ver esa evolución de manera sencilla.
![]()


autobus las palmas aeropuerto cetona de frambuesa