Actualidad informática
Noticias y novedades sobre informática

Detenido el administrador del «Ebay de las drogas»
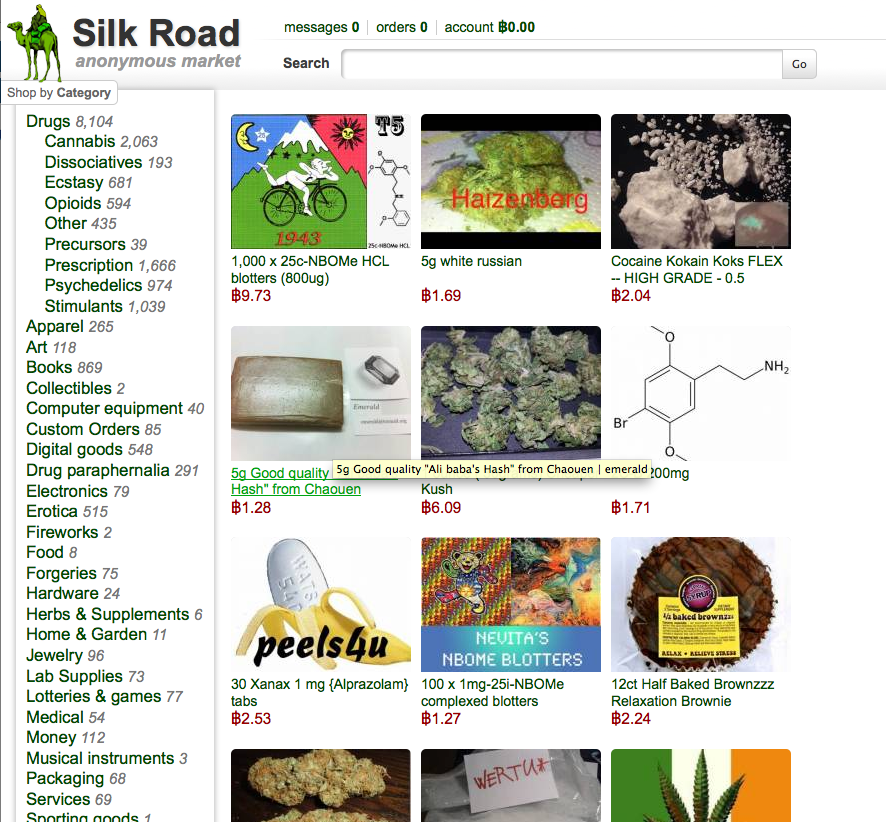
Después de casi tres años operando con total impunidad, las autoridades estadounidenses han conseguido cerrar la página web y encontrar al presunto administrador de Silk Road (ruta de la seda, en su traducción del inglés), una web con una estructura parecida a eBay en la que más de 150000 internautas han estado comerciando con estupefacientes de todo tipo desde febrero de 2011.
Nadie sabía quién estaba detrás de Dread Pirate Roberts, el apodo con el que escondía su verdadera identidad Ross William Ulbricht, un estadounidense de 29 años que ha sido detenido este miércoles en San Francisco en una operación conjunta entre la fiscalía, el FBI y la policía, según informa la agencia AFP.
El administrador del sitio se ha estado embolsando durante estos años comisiones de entre un 6% y el 10% de cada venta que se hacía a través de la página, llegando a ingresar cerca de un millón de dólares anuales (822,000 euros), según un estudio llevado a cabo por la universidad Carneggie Mellon de Pittsburg (EE. UU). Los agentes han incautado a Ulbricht bitcoins por valor de 3.6 millones de dólares (2.6 millones de euros), la mayor incautación de esta divisa hasta la fecha.
El FBI, en su escrito, acusa a Ulbricht de tráfico de estupefacientes, piratería informática y lavado de dinero, pero también de pagar 150000 dólares (110000 euros) a un usuario de Silk Road para que asesinara a otro internauta que amenazaba con revelar los datos de todos los miembros de la página. El FBI no ha logrado, sin embargo, determinar si realmente el crimen se consumó ya que en los registros de la zona en la que debía llevarse a cabo no figura registrado ningún asesinato.
Ampliar en: El Indagador Tecno-científico
![]()
15 años de Google
Un día como hoy pero de 1998 Google fue lanzado por Larry Page y Sergey Brin, que en un inicio fue llamado BackRub, pero que es hoy por hoy una de las compañías más importantes del mundo tecnológico.
Es difícil imaginar como un gigante como Google, que hoy no sólo se enfoca en búsquedas si no que ofrece software, servicios y dispositivos, empezó siendo un pequeño proyecto por parte de los dos estudiantes de doctorado.
La interfaz del diseño de Google fue tan sencilla porque Page y Brin no sabían HTML y querían un diseño rápido.
Fuente: Conecti.ca
![]()
Razones frente a los mitos de la imagen distorsionada de internet

Hay razones para esta imagen distorsionada de internet. Pero antes de exponerlas déjeme indicar por qué es distorsionada, usando los datos existentes, a cuya consulta le remito para ahorrar palabras. Si le interesa vea las webs del World Internet Project, del Pew Institute, del Oxford Internet Institute o del Projecte Internet Catalunya de la UOC, entre otras muchas. Todos los análisis disponibles concurren en desmentir una serie de mitos.
Primer mito: internet aísla, aliena, deprime. Es lo contrario: usar internet aumenta la sociabilidad, dentro y fuera de la red, porque los dos tipos de sociabilidad se acumulan. Las redes sociales sirven para mantener vínculos originados fuera de la red al tiempo que crean nuevas oportunidades de amistad y relación. Y cuando hay personas que sufren de aislamiento o depresión, la red ayuda a encontrar compañía. En realidad el BCS Institute inglés, con una muestra mundial, encontró una correlación entre internet y los índices de felicidad, porque incrementa sociabilidad y empoderamiento, factores clave inductores de felicidad.
Segundo mito: la divisoria digital. En términos de acceso, en los países desarrollados como España, el acceso a internet (desde distintos lugares y plataformas) oscila entre el 70% y el 90% y supera el 85% en la población adulta de menos de 60 años, porque el principal factor del no uso es la edad, así que cuando mi generación haya desaparecido el uso de internet será universal. En el mundo hay 2800 millones de usuarios de internet y 6700 millones de usuarios de móviles, o sea, que la humanidad está conectada. Obviamente, hay desigualdad en la calidad de la conexión, pero dicha desigualdad es menor que en otros indicadores de desigualdad, como patrimonio o renta, porque la gente otorga un valor prioritario a sus prácticas de comunicación.
Tercer mito: internet maleduca a los niños porque no prestan atención en clase y se distraen en casa. Lo que nos dicen los estudios sobre el abandono escolar es que la escuela (no los maestros, que hacen todos sus esfuerzos) no ha entrado en la pedagogía de la era digital y sigue aferrada a libros de texto, negocio editorial y propaganda de las ideologías oficiales. Resultado: los adolescentes, que viven plenamente en la creatividad de la cultura digital, se aburren soberanamente en clase y, en cuanto encuentran alternativa, se largan a la vida, que es más interesante. Cierto que internet requiere menos memorización, porque todo está en la red, pero al mismo tiempo ofrece múltiples posibilidades de recombinar información, que es la base de la creatividad. Como nuestra cultura está basada en la transmisión disciplinada de lo adquirido, está mal visto que los niños piensen por sí mismos, ayudados por maestros que les capaciten para buscar y usar la información enfocada a sus proyectos. Y nuestra economía del conocimiento y nuestra sociedad en cambio continuo requieren sobre todo personas capaces de improvisar e innovar, no de repetir gestos rutinarios.
Cuarto mito: la educación universitaria virtual degrada la calidad por la falta de contacto con el profesor. De hecho, el contacto con el profesor es mucho más limitado en las universidades tradicionales que en las virtuales con calidad basada en tutorías. Y además, las virtuales se dirigen mayoritariamente a una población adulta que sin esa educación no tendría posibilidad de estudiar y reciclarse. Siendo así que el aprendizaje a lo largo de la vida es esencial en una economía en constante transformación.
Quinto mito: internet es el Gran Hermano donde todo se sabe y se vigila. Es cierto que la privacidad en internet es difícil, pero a cambio sabemos que la denuncia del abuso, los movimientos sociales y la resistencia a tiranías encuentran en internet un instrumento esencial de autoorganización y movilización. Internet autonomiza y empodera: los vigilantes también son vigilados.
Sexto mito: la información en internet no es fiable. Mucha no lo es, otra sí, como en los medios de comunicación, pero a diferencia de estos, en internet se puede comentar y corregir mediante la participación activa de múltiples productores de información. Séptimo mito: internet es causante de violencia, terrorismo, pornografía, sexismo y toda clase de aberraciones. Se olvida que estas lacras son rasgos de nuestras sociedades y por tanto también existen en internet. Es cierto que la viralidad en internet incrementa riesgos, por ejemplo la difusión de técnicas terroristas o propaganda extremista. Pero es que internet es libertad y los usos de la libertad son reflejo de quienes somos, de modo que somos nosotros los que tenemos que cambiar en lugar de ocultarnos la verdad.
La imagen deformada de internet proviene del tremendismo de los medios de comunicación, aterrados por su supervivencia como medios unidireccionales controlados por el dinero y el poder, a pesar del periodismo profesional. De la fobia de intelectuales que perdieron el monopolio de la palabra. Del miedo de los gobiernos a una ciudadanía informada, capaz de autocomunicarse y autoorganizarse. Del temor de burocracias que basan su autoridad en el control de la información. Y de nuestro espanto a saber quiénes somos tras las celosías de la hipocresía social. Temer a internet es temer la libertad.
Fuente: Caffe Reggio
![]()
El origen del error ‘404’
En el inicio de los tiempos, cuando Internet era un mundo extraño en la que todo se llevaba a cabo mediante consola y compartiendo archivos, un grupo de jóvenes científicos del CERN (Suiza) se dedicó a lanzar la World Wide Web, conocida mundialmente como “www”.
Ellos esperaban crear una infraestructura necesaria para tener acceso a contenido en varios formatos que estuviera en las computadoras conectadas a esta red y que combinara texto e imágenes.
Estos chicos empezaron a probar este protocolo dentro del mismo CERN, con la red de computadoras que había ahí mismo. Empezaron por usar la infraestructura del CERN para alojar a la naciente Internet.
En una habitación del cuarto piso (la habitación 404) les permitieron poner lo que sería la base central de la red, cualquier petición de ficheros por parte de un usuario era encaminada a esta oficina donde dos o tres personas se encargaban de localizar el archivo manualmente y mandarlo hasta el usuario que lo había solicitado. Todo a través de la red.
¿Pero qué pasaba cuando los chicos de la oficina 404 no podían encontrar el archivo o este no existía? Pues ellos se encargaban de mandar un mensaje que dijera “Room 404: file not found”.
Cuando el Internet se mundializó, el error 404 se siguió manteniendo y hasta nuestros días se puede ver cuando escribimos mal una dirección o cuando la página o archivo que buscamos en Internet ha sido borrado.
Fuente: CULTURIZANDO
![]()
Los “me gusta” en Facebook influyen más que los “no me gusta”

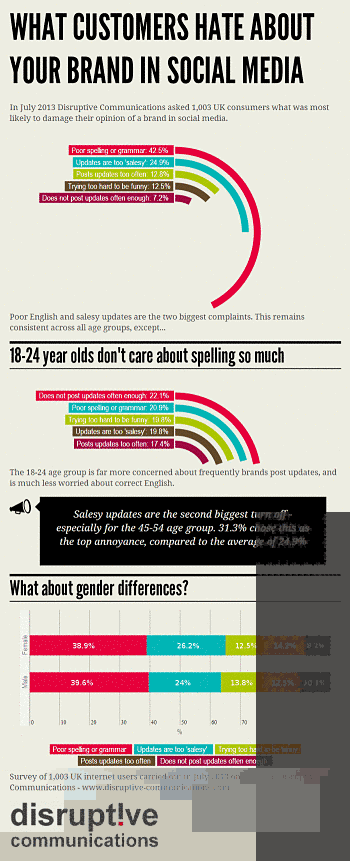
Las opiniones positivas influyen más que las negativas, al menos en Internet. Esta es la conclusión de científicos de varias universidades tras analizar comentarios de las redes sociales Facebook y Reddit. El estudio Polarización de la influencia social: un experimento aleatorio ha sido publicado en la revista Science.
Mientras que las reacciones positivas crean un efecto «manada», escriben los autores, las opiniones negativas no parecen afectar a la gente de la misma manera. La influencia social negativa tiende a corregir las calificaciones, mientras que la probabilidad de que un comentario positivo arrastre a otro es del 32% y, finalmente, la experiencia enseña que los «me gusta» acarrean de promedio una acumulación de un 25% más de reacciones favorables. En otras palabras, las personas creen que el autobombo puede ayudar en un primer momento. Pero eso no es siempre es bueno, advierten los investigadores.
«Si alguien hace un comentario sobre un producto que quiero comprar, supongo que es útil si se ha votado y no es útil si se votó en contra», dice Matthew O. Jackson, profesor de economía en la Universidad de Stanford, que participó en la investigación.
Por categorías, los post de política, cultura, sociedad y empresas generan el mayor efecto de arrastre positivo, y los comentarios de economía, informática, diversión y noticias en general los que menos.
Cuando los investigadores alteraron las calificaciones en un sentido negativo, las personas fueron más escépticas, y propensas a anular un voto negativo con uno positivo. «Probablemente ver algo positivo te hace sentir mejor, y si ves algo negativo tu reacción es tratar de dejarlo en una posición neutral», señala Jackson.
Durante cinco meses, los investigadores alteraron aleatoriamente las calificaciones de 101000 comentarios. Aquellos manipulados para ser más positivos obtuvieron un tercio de más «me gusta» que los comentarios no alterados.
Los resultados publicados ayer sugieren un cierto escepticismo sobre el uso del juicio colectivo para evaluar la calidad de los productos o ideas, según los investigadores.
«Estas opiniones positivas también representan prejuicios y ocasionan inflación», dijo Sinan Aral, uno de los tres autores del estudio, profesor del Sloan School of Management. «La burbuja inmobiliaria fue un derroche de positividad, pero cuando estalló, algunas personas perdieron sus ahorros y sus casas».
Fuente: TECNOLOGÏA ElPaís.com
![]()
Test Público Completamente Automatizado para Diferenciar a los Seres Humanos de las Computadoras, Captcha
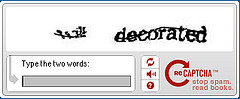
Las siglas inglesas de Completely Automated Public Turing Test to Tell Computer and Human Apart (Test Público Completamente Automatizado para Diferenciar a los Seres Humanos de las Computadoras) quizá os suenen más si las resumimos en el término más familiar Captcha.
Pero ¿qué utilidad tienen realmente estas palabras que aparecen en muchos sitios de Internet y quedebemos reproducir con nuestro teclado, en ocasiones forzando al máximo nuestra capacidad de lectura? (en mi caso, muchas veces me equivoco, lo cual me debe emparentar más con una computadora que con un humano).
Los Captcha llegaron para controlar el caos de spam generado en la década de 1990 en el ámbito de Internet. Los spambots inundaban los buzones de entrada del correo electrónico, y jalonaban los foros online. Pero todo esto cambió en el año 2000 gracias a un joven de 22 años.
Luis von Ahn, recien licenciado en la universidad, tuvo una idea para acabar con el spam: obligar a los que se inscribieran a probar que eran seres humanos y no un maldito bot. Así que buscó algo que resulta fácil para los seres humanos, pero no tanto a las máquinas: reconocer letras.
Se le ocurrió entonces presentar letras garabateadas y difíciles de leer durante el proceso de registro,y dejar solo unos segundos para descifrarlas y reproducirlas. Cuando Yahoo implementó este sistema, redujo los spambots de forma considerable en solo 24 horas.
A raíz del desarrollo de los Captcha, Von Ahn obtuvo un puesto como profesor de informática en la universidad Carnegie Mellon, así como contribuyó a que recibiera uno de los prestigiosos premios “genio” de la fundación MacArthur, dotado con medio millón de dólares. Sin embargo, algo fallaba aún.
El mayor error de los Captcha pasaba por exigir a los usuarios un montón de esfuerzo y tiempo colectivo para nada, o simplemente para evitar el spam. Un tiempo y un esfuerzo computacional humano que Von Ahn trató de darle utilizar inventando un sucesor de Captcha: ReCaptcha.
Con este nuevo sistema, la gente ya no teclea letras aleatorias, sino que teclea dos palabras procedentes de proyectos de escaneo de textos que el programa de reconocimiento óptico de caracteres de un ordenador no podría entender. La primera palabra sirve para confirmar lo que han introducido otros usuarios, y es que, por consiguiente, una señal de que el usuario es humano. La otra palabra es una palabra nueva que precisa de desambiguación.
Para garantizar que el sistema es efectivo, el sistema presenta la misma palabra borrosa a una media de 5 personas diferentes que la deben insertar correctamente antes de aceptarse como válida. Lo que ahorra mucho tiempo y dinero, tal y como explican Viktor Mayer-Schonberger y Kenneth Cukieen Big Data:
Con aproximadamente diez segundos por uso, 200 millones de ReCaptchas diarios ascienden a medio millón de horas diarias. El salario mínimo en Estados Unidos era de 7,25 dólares brutos por hora en 2012. Si uno tuviera que dirigirse al mercado para desambiguar las palabras que un ordenador no había conseguid descifrar, costaría alrededor de cuatro millones de dólares diarios, o más de mil millones de dólares al año.
Esta clase de trabajo colaborativo basado en el ingente número de datos que dejamos por nuestro paso por la Red es indudablemente la forma en la que muchos proyectos del presente y del futuro próximo están prosperando para mejorar nuestra calidad de vida o para afrontar problemas que de otro modo serían irresolubles. Como la web donde te predicen si tu vuelo se retrasará o se cancelará.
Fuente: Xataka CIENCIA
Licencia CC
![]()
Como circula la información por internet
Conocer el cable exacto que toma cada conexión no es posible y aquí se han escogido algunos ejemplos de recorridos típicos basados en la información de muchas conexiones. El punto de partida, en este caso es Alemania, pero se podría hacer uno muy parecido desde España. La aplicación también te informa de los accesos desde los que PRISM puede estar obteniendo tus datos. La velocidad está ralentizada, ya que todo esto que veis se produce en milésimas de segundo. Para usar el mapa, dale a los botones de la parte superior y observad el recorrido. En la web de OpenDataCity se ve mejor. Vía @pablo_gutierrez
Esta infografía interactiva muestra varios ejemplos de las rutas que recorren los paquetes de información cuando utilizamos un servicio como Google, Facebook o Amazon. La aplicación está diseñada combinando los datos de cableado de cablemap.info y el programa Traceroute.
Conocer el cable exacto que toma cada conexión no es posible y aquí se han escogido algunos ejemplos de recorridos típicos basados en la información de muchas conexiones. El punto de partida, en este caso es Alemania, pero se podría hacer uno muy parecido desde España. La aplicación también te informa de los accesos desde los que PRISM puede estar obteniendo tus datos. La velocidad está ralentizada, ya que todo esto que veis se produce en milésimas de segundo. Para usar el mapa, dale a los botones de la parte superior y observad el recorrido. En laweb de OpenDataCity se ve mejor.
Fuente: Fogonazos
Licencia CC
![]()
El primer sitio web del mundo, bloqueado por una contraseña olvidada
El olvido de la contraseña de una antiguo ordenador está dificultando la labor de un equipo de científicos del Centro Europeo de Física de Partículas (CERN) que intenta reconstruir el primer sitio web de la historia y devolverlo a su dirección original.
«Internet y la web crean grandes cantidades de información, pero también la destruyen. Son medios poderosos, pero frágiles al mismo tiempo. El olvido de una simple contraseña provoca la pérdida de valiosa información», explicó en una entrevista a Efe Dan Noyes, jefe de ese equipo.
Corría el año 1989 y desde su computadora Next, en una pequeña oficina del CERN, el físico Tim Berners-Lee recurrió a internet -que ya existía- para desarrollar un sistema de intercambio de información entre científicos de diferentes universidades y laboratorios del mundo, que con el tiempo vendría a ser conocido como la web.
A través de ese sistema, se podían leer y publicar documentos, así como crear enlaces entre ellos.
En ese primer sitio web, hecho de distintas «páginas» en blanco y negro y «links» entre ellas en color azul, su creador explicaba cómo acceder a la web o a los documentos de otras personas, o la manera de configurar un servidor propio.
Cuatro años más tarde, el CERN publicó una declaración en la que autorizaba la utilización gratuita y libre de esta tecnología, una decisión crucial para su expansión y que fue el origen de la revolución de la información.
Durante el tiempo en que esta tecnología tuvo un uso exclusivamente académico, el primer sitio web fue cambiando al mismo tiempo que su creador editaba continuamente sus contenidos.
«No existe el primer sitio web porque se escribió sobre él. Existió durante un tiempo muy limitado, quizás unos meses, unos días o tal vez horas», dijo a Efe el editor del actual sitio web del CERN, Cian Micheal, quien trabaja en el equipo que pretende dar a conocer al mundo el primer prototipo de Berners-Lee, quien no había cumplido los 35 años cuando formuló su invención.
El proyecto de reconstrucción fue anunciado públicamente por el CERN con ocasión del vigésimo aniversario del libre acceso a la web.
La primera copia que se ha logrado reconstruir data de 1992 (http://info.cern.ch/hypertext/WWW/TheProject.html), pero en el CERN están seguros de la existencia de otra copia de 1991 localizada en el ordenador bloqueado de un profesor de la Universidad Chapel Hill en Carolina del Norte Paul Jones.
Jones conoció a Berners-Lee en una conferencia en San Antonio (EEUU) y se interesó tanto por el proyecto World Wide Web (WWW) que hizo una copia de los ficheros que la web contenía hasta aquel momento.
«Desafortunadamente, la computadora Next de Jones se encuentra bloqueada por una palabra de acceso que él mismo olvidó y expertos informáticos están actualmente intentando recuperar esa información», explicó Noyes.
Posteriormente, el disco duro con otra copia de una de las primeras versiones de la web fue robado o se extravío en un hotel -la verdad se desconoce- durante una presentación que Berners-Lee hizo del proyecto WWW a principios de los noventa en San Diego (EEUU).
La tarea por tanto no es fácil, pero Noyes cree que esta «abrumadora» búsqueda vale la pena porque hará que los usuarios se den cuenta de la fragilidad de la información virtual.
Contrariamente a una carta de amor con sobre y sello, un correo electrónico desaparecerá eternamente si se pierde una contraseña.
«Si personas famosas como Shakespeare hubiesen vivido en la era tecnológica, toda la información que conocemos de ellos por su correspondencia se habría perdido para siempre por no conocer una palabra de acceso», recalcó.
Internet, que nació en los años sesenta, es un sistema que permite la conexión entre distintas computadoras; mientras que la web es uno de sus principales servicios, que permite publicar y compartir documentos.
Fuente: lainformación.com
![]()

autobus las palmas aeropuerto cetona de frambuesa