Actualidad informática
Noticias y novedades sobre informática
Historia del comercio electrónico desde 1960

La siguiente cronología muestra los logros relacionados con el comercio electrónico, logros que hasta el día de hoy se continúan dando para mejorar e innovar.
- 1979 Michale Aldrich inventa las compras online: Aldrich fue un inventor británico que creó una serie de cosas, incluyendo la Teleputer, que era un centro de entretenimiento por computadora. En 1979 se desarrolló un predecesor de compras en línea para permitir el procesamiento de transacciones en línea para las necesidades de B2C (Negocio a Cliente) y B2B (Negocio a Negocio).
- 1981 Thomson Holidays hizo la primera transacción electrónica B2B usando la tecnología en línea. Thomson Holidays era un operador de viajes del Reino Unido que usó la tecnología en línea para que los clientes reservaran en línea y pagaran en línea.
- 1982 France Telecom inventa Minitel, considerado como el más exitoso del mundo, antes de la llegada de los servicios en línea por la World Wide Web. Los usuarios podían realizar compras en línea, reservas de tren, y más a través del servicio Videotex en línea, accesible a través de líneas telefónicas.
- 1984 Jane Snowball de 72 años de edad, fue el la primera compradora de una vivienda en línea. Ella utilizó el sistema Gateshead SIS/Tesco para comprar en línea.
- 1987 se creó la primera cuenta de comercio electrónico por SWREG. Fue creado para que los desarrolladores de software puedan vender sus soluciones en línea.
- 1990 Tim Berners-Lee desarrolló el primer navegador web utilizando una computadora NeXT, creando así la World Wide Web.
- 1991 La National Science Foundation (NSF) levantó las restricciones sobre el uso comercial de la red, lo cual abrió el camino para el comercio electrónico.
- 1992 J.H. Snider y Siporyn Terra publicaron Future Shop: “Cómo las nuevas tecnologías cambiarán la manera de comprar y lo que compramos”. Este libro fue un predictor increíble del futuro del e-commerce.
- 1994 Este fue un gran año de novedades en el comercio electrónico. Se lanzó el navegador Netscape Navigator, el cifrado SSL se convirtió en una realidad (para asegurar las ventas en línea), Pizza Hut tuvo la primera venta registrada por Internet (una pizza de peperoni y champiñones con queso extra), se abrió la primera línea bancaria, se construyeron las primeras soluciones de comercio electrónico por los mismos comerciantes para vender en línea, y se produjo el primer mensaje de Spam por correo electrónico (conocido como el Spam Green Card)
- 1995 La burbuja de las punto-com comenzó con la salida de Netscape a la bolsa de valores. Mientras tanto, Jeff Bezos, se sentó en un garaje en Bellevue, WA a empezar Amazon.com. En el sur de California eBay comenzó como “AuctionWeb“. Se lanzó Craigslist y VeriSign se lanzó como una forma de verificar comerciantes en línea.
- 1997 Dell.com se convirtió en la primera compañía en ganar $1,000,000.00 en ventas en línea.
- 1998 El US Postal Service entró en el espacio del comercio electrónico mediante la venta de sellos electrónicamente a través de e-stamp. Al mismo tiempo, dos estudiantes de Standford comenzaron sus planes para la dominación del mundo con el lanzamiento de Google.
- 1999 La Corte Suprema de EE.UU. dictaminó que los nombres de dominio son propiedad.
- 2000 La produjo caída de las punto-com
- 2002 eBay compró PayPal por $ 1.5 mil millones de dólares. Mientras tanto, se crearon nichos de tiendas al por menor tiendas de CSN y NetShops creó el concepto de la venta de productos a través de varios dominios en lugar de un portal central.
- 2003 Facebook comenzó como un sitio web de la universidad llamado Facemash, que permitía a los estudiantes calificar si otros estudiantes en la escuela tenían buen aspecto. Al mismo tiempo, Amazon registró su primer año rentable. Por último, la ley CAN-SPAM del 2003 cambió para siempre el “email marketing“, descartando a los vendedores que pudieran hacer Spam siempre y cuando siga ciertas normas.
- 2005 Llega la web 2.0 haciendo los sitios web más interactivos y el Software de comercio electrónico VirtueMart llega a su versión final.
- 2006 Google compró YouTube. En el mismo año, Sex.com se vendió por 14 millones de dólares, el cual era el mayor precio de venta registrado para un nombre de dominio. Por último, iTunes se convirtió en el mayor vendedor de música digital con más de mil millones de descargas.
- 2007 Apple lanza el iPhone, con un navegador web completo, lo cual es un gran avance para el comercio electrónico a través de los móbiles. Se lanzó el software libre Prestashop para crear tiendas en línea. También los usuarios de banda ancha en Estados Unidos llegaron a los 200 millones, lo que ayudó al éxito del comercio electrónico para las empresas pequeñas y grandes. Google Adwords superaron los $21 mil millones en ingresos.
- 2008 Se lanza la solución de comercio electrónico Magento por la empresa Varien.
- 2009 Yahoo y Bing se unieron para competir mejor contra Google. Cerca del final de 2009, Facebook ha avanzado en el tráfico y ha alcanzado a Google.
- 2010 El comercio electrónico toma en serio el “Social Media” lo cual deriva en conversaciones más personales entre las tiendas y sus clientes. Se lanza Magento Mobile permitiendo a los vendedores minoristas crear tiendas en línea para móviles.
- 2011 En todo el mundo, un 60% de personas han realizado compras online alguna vez. El 14% de las compras en línea se realizaron desde dispositivos móviles y el 18% de las visitas a las tiendas en línea fue a través de dispositivos móviles.
- 2012 Se dio auge de terceros proveedores de comercio electrónico que ofrecen la simplicidad de instalación y mantenimiento del sitio con el fin de atraer a las empresas, los más populares son Volusion y Shopify.
Fuente: Carlos Leopoldo
Techtástico – Contenido bajo licencia C.C. 2012
![]()

Cinco aspectos de los medios sociales que aún se les resisten a las empresas

Estos son los cinco aspectos en los que, en opinión de Schwartz, más patinan las empresas que se adentran en la Web 2.0 con una disposición -o asesoramiento- equivocada:
- Spam -> “Muchas compañías sólo utilizan las redes sociales para lanzar eslóganes comerciales”.
- Obsesión por el número de seguidores/fans -> “Si bien es cierto que los seguidores son necesarios para construir una audiencia que garantice la eficacia del proyecto, la cantidad es menos importante que la calidad”.
- Hablar mucho/escuchar poco -> “Ya sea para obtener el feedback de tus clientes, para ver lo que dicen tus competidores o para conseguir una impresión general de las tendencias emergentes, las redes sociales no están solo para difundir los logros y las ideas de su empresa, también son ideales para escuchar lo que otros dicen”.
- Oídos sordos a los intereses de los usuarios -> “La gente suele usar los medios sociales como caja de resonancia pública para expresar sus quejas y reclamaciones. Usted debe ser capaz de entablar conversaciones con las personas sobre la base de sus exigencias”.
- Ausencia de compromiso con el medio -> “Muchas compañías abren una cuenta de Twitter, o un perfil de LinkedIn, y luego no hacer nada con ella. Incluso unos pocos minutos al día pueden provocar un gran cambio en su negocio, pero usted tiene que volcarse y demostrar que su empresa está “aquí para quedarse” en la revolución del social media”.
Fuentes: Mangas Verdes
![]()
Teletransporte cuántico mediante satélites, aplicable a internet
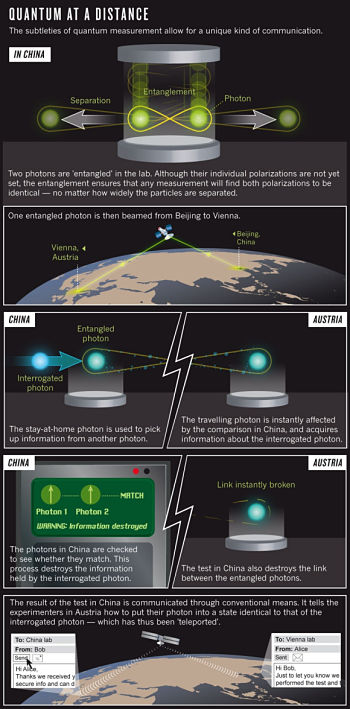
El chino Jian-Wei Pan estudió los secretos del teletransporte cuántico sin cables en el laboratorio del austríaco Anton Zeilinger. El 8 de agosto de 2012 publicó en Nature su récord de 92 km de distancia en China, pero le duró muy poco, fue superado el 5 de septiembre por su maestro, quien alcanzó 144 km en las Islas Canarias. La única posibilidad de lograr una distancia aún mayor es utilizar un satélite.
El objetivo de Pan y Zeilinger a largo plazo es lograr una internet cuántica que conecte todo el globo terrestre, similar a la internet convencional. Por supuesto, aún quedan muchas décadas para lograrlo. Sin embargo, el teletransporte cuántico vía satélite podría abrir una puerta a ciertos tests del efecto de la gravedad en el teletransporte cuántico, lo que podría aportar cierta información sobre la gravedad cuántica [nos los cuentan Giovanni Amelino-Camelia, Lee Smolin y varios colegas].
Ampliar en:
Francis (th)E mule Science’s News
Teleportación: La carrera espacial cuántica
![]()
Contra las letras en mayúsculas en las páginas web

ALL-CAP TEXT REDUCES READING SPEED BY ABOUT TEN PERCENT. MIXED-CASE LETTERS HAVE VARIATIONS THAT BREAK UP THE TEXT INTO RECOGNIZABLE SHAPES, WHEREAS A PARAGRAPH IN ALL CAPS HAS UNIFORM HEIGHT AND SHAPE, MAKING IT APPEAR BLOCKY AND RUN TOGETHER. ALSO, THE USO OF ALL CAPS CAN SEEM CHILDISH AND AMATEUR, OR AGGRESSIVE OR UNPROFESSIONAL. RESERVE ALL-CAP TEXT FOR SHORT HEADINGS AND TITLES, AND FOR SHOUTING.
Traducción:
TODO EL TEXTO EN MAYÚSCULAS REDUCE LA VELOCIDAD DE LECTURA APROXIMADAMENTE EN UN DIEZ POR CIERTO. LAS LETRAS EN MAYÚSCULAS Y MINÚSCULAS TIENEN VARIACIONES QUE ROMPEN EL TEXTO EN FORMAS RECONOCIBLES, MIENTRAS QUE UN PÁRRAFO TODO EN MAYÚSCULAS TIENE UNA ALTURA Y FORMA UNIFORMES, HACIENDO QUE PAREZCA FORMA POR BLOQUES Y TODO JUNTO. ADEMÁS, LA UTILIZACIÓN DE TODAS LAS LETRAS EN MAYÚSCULAS PUEDE PARECER INFANTIL Y DE AFICIONADOS, O AGRESIVO O POCO PROFESIONAL. RESERVA TODO EN MAYÚSCULAS PARA LOS ENCABEZADOS Y TÍTULOS CORTOS, Y PARA GRITAR.
Prioritizing Web Usability. Jakob Nielsen, Hoa Loranger. New Riders, 2006.
Fuente: PROGRAMACIÓN EN INTERNET
![]()
El CERN será de los primeros en usar la red de 100 Gbps de GEANT
El LHC genera alrededor de 30 Petabytes (un Petabyte = 1 000 000 Gigabytes) cada año por lo que necesita tener conexiones rápidas para poder distribuir los datos a los centros de análisis que colaboran con el CERN y que están repartidos por todo el mundo.
GEANT es la herramienta capaz de facilitar esta tarea. GEANT es la red europea para la comunidad investigadora y educativa. En ella participan las redes nacionales de investigación y educación (NREN) de Europa. Incluye instituciones con proyectos que van de la física de partículas al arte. Cuenta con más de 50000 km de conexiones y es usada por 40 millones de usuarios. Además proporciona uniones globales con otros centros de dato del resto del mundo.
El proyecto de GEANT es aumentar la velocidad hasta los 2 Tbps (terabits por segundo) en 2020 en toda Europa. El reto para el CERN es conectar el nuevo centro de cálculo a la red nacional húngara y por lo tanto a GEANT para conseguir que realmente Wigner sea una extensión del CERN.
Fuente: La Hora Cero
![]()
Hay bits que viajan en primera
Charla impartida por Juanjo Unzilla, profesor de Ingeniería Telemática en la Escuela Superior de Ingeniería de la UPV/EHU (Esuskadi), que ha tratado sobre la configuración de las redes de transmisión de información, y sobre el modo en que se organiza el tráfico de la misma entre los diversos dispositivos (móviles y ordenadores, principalmente) y a través de las redes de comunicación.
![]()
Extensión que descarga contenidos a Google Drive
Si usamos Google Chrome y queremos simplificar el proceso de descarga de algunos contenidos (descargarlos en nuestro ordenador para indicar que se almacenen en la carpeta de Google Drive o tener que moverlos desde la carpeta de descargas a la de Drive) recurrir a la extensión Save to Drive quizás pueda servirnos de mucha ayuda.
Con esta extensión podremos almacenar directamente en Google Drive imágenes, audio y vídeo en HTML5 (en flash no está soportado) y enlaces que vayamos encontrando por la red. De la misma forma que posicionaríamos el puntero del ratón sobre una imagen y pulsaríamos el botón derecho para activar el menú y seleccionar “guardar imagen como”, por ejemplo, si tenemos instalada esta extensión observaremos una nueva entrada en el menú denominada “Guardar imagen en Google Drive” que, directamente, la almacenará en el raíz de nuestro espacio de almacenamiento en Google.
Algo parecido también podremos hacer con los enlaces que encontremos aunque, en el caso de un enlace a una página, la extensión almacena el código HTML del destino, sin embargo, si nos encontramos cualquier enlace de descarga (un documento PDF, un archivo comprimido, etc) sí que se almacena directamente en Google Drive.
La extensión no requiere configuración alguna y aunque pudiese parecer un aspecto favorable, no hay opción a definir una carpeta destino de las descargas y todo se deja en el raíz, por lo que tendremos que ir ordenando los archivos de manera manual.
Fuente: bitelia
![]()
Las redes sociales y las elecciones en EE.UU.
Cada año electoral en EEUU es un hervidero de artículos sobre el papel de la web y las redes sociales (Facebook, Twitter y YouTube) a la hora de predecir el resultado. Como solo hay un 50% de posibilidades de acertar (o errar) siempre hay artículos cuyos autores pueden presumir de haber acertado, incluso en más de una ocasión. Sin embargo, los medios de comunicación social y los resultados de los algoritmos de análisis pueden ser fácilmente manipulados. Por ejemplo, alterando el número de seguidores de los candidatos en Twitter (uno de los candidatos presidenciales de este año aumentó su número de seguidores en 110000 en un solo día, pero un análisis demostró que la mayoría de estos seguidores no eran personas reales). Los organizadores de la campaña utilizan de forma regular “Google bombs” (que engañan al algoritmo PageRank de Google y logran posicionar ciertos sitios web en los primeros lugares en los resultados de búsqueda para ciertos términos) y ”Twitter bombs” (que logran trending topics gracias a retuitear de forma automática los tuits que incluyen cierta etiqueta o hashtag). Predecir los resultados electorales de forma fiable gracias a la web y las redes sociales requiere técnicas avanzadas de detección de “bombas” y de spam, técnicas contra las que compiten los desarrolladores de “bombas.” Por ello, algunos algoritmos tienen éxito en sus predicciones y otros no, o solo en algunas ocasiones y no en otras.
Los anuncios en los medios utilizados durante la campaña de un candidato presidencial pueden ser positivos (elogiando al candidato), negativos (en contra del otro candidato) o neutros (centrados en el contenido del programa electoral). El número de anuncios políticos negativos ha crecido desde 2000, en detrimento de los anuncios positivos. Un nuevo estudio afirma que el impacto de la publicidad negativa en las campañas políticas es mayor a finales de la campaña (en octubre en el caso de EEUU), más aún, al contrario de lo que se pensaba, incrementa la participación de los electores y es buena para la democracia (como ya indicó el politólogo John Geer en su libro “In Defense of Negativity,” publicado en 2006). Por supuesto, las cosas nunca son tan simples. Nos lo cuenta Eliot Marshall, “Want to Tear Down Your Rival? Here’s What Might Work Best,” Science 338: 465, 26 October 2012.
Son interesantes las charlas de la 6ª Jornada Tecnológica del Instituto de Ingeniería del Conocimiento (IIC 2012), los vídeos de las charlas aparecen en youtube. Es de destacar la de Esteban Moro (@EstebanMoro), “Marketing por influencia social y sus algoritmos”.
Ampliar en: Francis (th)E mule Science’s News
![]()
El lado oculto de internet
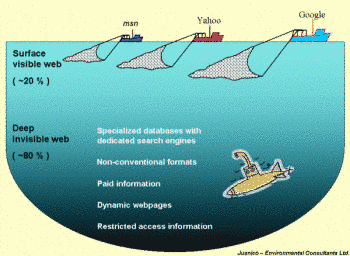
Internet, esa inmensa red de ordenadores conectados en la que se puede compartir información. Ese entramado de conexiones que recuerdan a una tela de araña en el que nos pasamos tantísimas horas para entretenernos, para compartir o para buscar información. Creemos conocer dónde encontrar casi todo, pero quizá nos sorprenda saber que la parte que “conocemos” de internet no es más que una ínfima porción de un inmenso océano de información, una ingente cantidad de información que se encuentra a más profundidad, lejos de las arañas de los buscadores.
¿Cómo existe la internet profunda?
El trabajo de los buscadores los hacen sus «arañas», un particular nombre para un software que se dedica a recorrer la red en busca de páginas y de la información que contienen. Seria absurdo y tremendamente lento que fuera en el momento de la búsqueda el buscador se dedicara a rebuscar en internet aquello que buscamos. Por eso manda a sus arañas en busca de información que luego clasifica por diferentes temáticas en una gigantesca base de datos. De esta forma cuando nosotros buscamos algo nos puede devolver resultados en cuestión de segundos, millones de ellos.
No todo es accesible, ni todo cumple los mínimos para que una araña de cualquier buscador pueda acceder a la información que una página contiene. De hecho, los buscadores no son capaces de indexar el 95% de la información existente en internet. Y esto ocurre por diversos motivos, entre los principales se encuentran que los sitios a los que no pueden acceder los rastreadores están protegidos con contraseña, grandes bases de datos, documentos y otros archivos de formatos no indexables, y todas aquellas bases de datos que han de ser “interrogadas” para que devuelvan resultados (por ejemplo las de diccionarios). Evidentemente también forman parte del internet profundo todas aquellas página que no “quieren” ser vistas.
los buscadores pueden compararse con grandes redes de arrastre. Una gran cantidad de cosas pueden arrastrarse con la red en la parte más superficial , pero hay una gran cantidad de información que queda en la profundidad y que se pierde. Y es por este mismo motivo que la internet profunda es de una magnitud enorme. Según un estudio de la Universidad de Berkeley se estima que actualmente la internet profunda debería tener un tamaño aproximado de unos 91000 Terabytes, esto es unas 550 veces más grande que el internet convencional.
Fuente: OMICRONO
Bajo licencia Creative Commons
![]()

autobus las palmas aeropuerto cetona de frambuesa