Actualidad informática
Noticias y novedades sobre informática
FreshWebSuction programa para descargar web completas

FreshWebSuction es un programa gratuito y muy fácil de usar, para instalar bajo Windows. Permite descargar una página web completa incluyendo lo que desee. de sus archivos, tales como: imágenes, ficheros comprimidos, ejecutables y documentos.
Lo primero que se le ha de indicar es la dirección de la página a descargar, a continuación se proporciona el nivel de profundidad, lo que significa el número de subenlaces a descargar. Si se ha seleccionado un nivel 1, descargará hasta los enlaces del índice, pero si eliges el nivel 2, se descarga lo de los enlaces que se encuentran en el índice y también los enlaces que están dentro de los primeros enlaces. El programa permite descargar 50 archivos simultáneamente.
Acceso a FreshWebSuction

Internet y el anti-conocimiento

Empiezo a estar un poco “mosca” con este mantra que se repite hasta la saciedad: en internet está todo. ¡Pues no! Sí hay muchas cosas, sobre todo en inglés, pero no está todo. Y aunque fuera así, ¿por qué creemos que eso es bueno? Piénselo un momento: ¿Tener acceso a cualquier cosa es lo mejor que nos puede suceder? Yo estoy con Radio Futura cuando cantaban aquello de “David Bowie lo sabe y tu mami también / hay cosas en la noche que es mejor no ver”.
Dicen que con Internet hemos entrado en la era de la información, y es verdad. Incluso se han inventado un término, infoxicación, para definir un mal de nuestros tiempos: nos llega más información de la que podemos procesar y eso nos crea angustia. Un estudio realizado en 2002 por Peter Lyman y Hal Varian de la Universidad de Berkeley reveló que la información producida ese año equivalía a medio millón de nuevas bibliotecas, cada una conteniendo la versión digitalizada de las colecciones impresas de la mayor biblioteca del mundo, la Biblioteca del Congreso norteamericano.
A los santificadores de internet se les llena la boca con tales datos y sacan pecho; solo les falta decir que Internet es lo mejor que ha parido madre. Y podría ser así, pero olvidan una cosa fundamental: la información no es conocimiento. Y lo que hace progresar al ser humano es esto último.
El conocimiento exige tiempo y tranquilidad de espíritu para poder asimilar la información en condiciones, todo lo contrario a lo que sucede en esta época de Facebook y Twitter. Estos medios, con todas sus bondades, nos están llevando a una sociedad de conocimiento débil: ya no soportamos complejos razonamientos, sutiles argumentaciones que excedan de los 140 caracteres. Dicen que Internet hace que la gente lea más, pero es un argumento engañoso. Leer es un proceso en tres fases: hacerlo, entender lo que lees y finalmente digerirlo. Internet está promocionando la lectura rápida, mal entendida y regurgitada sin asimilar. Leemos algo y acto seguido contestamos con lo primero que nos viene a la cabeza. Claro que a lo mejor eso no es tan malo, que ya lo decía Jacinto Benavente: “cuando se habla sin pensar se dice lo que se piensa”
Autor: Miguel Ángel Sabadell
(Publicado en Muy Interesante)
Larry Page, CEO de Google explica las razones de la compra de Motorola Mobility
Larry Page, CEO de Google ha publicado en el blog oficial de la compañía las razones por las cuales han decidido comprar Motorola Mobility. En ALT1040 han hecho una traducción completa del texto:
Desde su lanzamiento en noviembre de 2007, Android no sólo ha aumentado considerablemente las opciones de elección de los consumidores, sino también la mejora de toda la experiencia móvil para los usuarios. Hoy, más de 150 millones de dispositivos Android se han activado en todo el mundo, con más de 550.000 dispositivos encendidos cada día a través de una red de alrededor de 39 fabricantes y 231 operadores en 123 países. Dado el éxito fenomenal de Android, que siempre están buscando nuevas maneras de impulsar el potencial del ecosistema Android. Es por eso que estoy tan emocionado de anunciar que hemos acordado la adquisición de Motorola.
Motorola tiene una historia de más de 80 años de innovación en tecnología de comunicaciones y productos, y en desarrollo de propiedad intelectual, que han ayudado a impulsar la notable revolución de la informática móvil que todos estamos disfrutando hoy. Entre sus muchos hitos en la industria, se incluyen: la introducción del primer teléfono celular portátil del mundo hace casi 30 años, y el StarTAC, el teléfono más pequeño y ligero que existía al momento de su lanzamiento. En 2007, Motorola fue un miembro fundador de la Open Handset Alliance que trabajó para hacer la primera plataforma Android verdaderamente abierta y completa para dispositivos móviles. Yo he amado todos mis teléfonos Motorola desde la época StarTAC hasta los actuales DROIDs.
En 2008, Motorola apostó en grande en Android como único sistema operativo en todas sus smartphones. Fue una apuesta inteligente y estamos muy emocionados por el éxito que han logrado hasta ahora. Creemos que su negocio móvil está en una trayectoria ascendente y preparada para un crecimiento explosivo.
Motorola también es líder de mercado en dispositivos del hogar y soluciones en vídeo para empresas. Con la transición a Internet Protocol, estamos muy contentos de trabajar junto a Motorola y la industria para apoyar a nuestros socios y cooperar con ellos para acelerar la innovación en este espacio.
El total compromiso de Motorola con Android en los dispositivos móviles es una de las muchas razones que demuestran que hay un encaje natural entre las dos compañías. Juntos vamos a crear increíbles experiencias de usuario que impulsarán el potencial de todo el ecosistema Android para el beneficio de los consumidores, socios y desarrolladores de todo el mundo.
Esta adquisición no va a cambiar nuestro compromiso para ejecutar Android como una plataforma abierta. Motorola seguirá siendo titular de una licencia de Android y Android permanecerá abierta. Vamos a llevar a Motorola como un negocio separado. Muchos de nuestros socios de hardware han contribuido al éxito de Android y esperamos seguir trabajando con ellos para proveer experiencias de usuario excepcionales.
Recientemente hemos explicado cómo compañías como Microsoft y Apple se están uniendo en causa común contra los ataques de patentes contrarias a la competencia en Android. El Departamento de Justicia de EE.UU. tuvo que intervenir en los resultados de una subasta de patentes recientes de “proteger la competencia y la innovación en la comunidad de software de código abierto” y actualmente está estudiando los resultados de la subasta de Nortel. Nuestra adquisición de Motorola permitirá aumentar la competencia mediante el fortalecimiento de la cartera de patentes de Google, que nos permitirá proteger mejor a Android de las amenazas anticompetitivas por parte de Microsoft, Apple y otras compañías.
La combinación de Google y Motorola no sólo impulsará el potencial de Android, sino que también mejorará la competencia y ofrecerá a los consumidores aceleración en la innovación, una mayor variedad y maravillosas experiencias de usuario. Estoy seguro de que estas grandes experiencias creará un enorme valor para los accionistas.

Bajo licencia Creative Commons Reconocimiento 2.5
Empieza a funcionar la primera web con dominio .xxx
Aunque se espera una avalancha en diciembre, ayer entró en funcionamiento ‘Casting.xxx’, la primera página con el dominio que identifica las webs calificadas como pornográficas.
A pesar de que por el momento no es obligatorio que las webs porno cambien a .xxx, el interés crece cada día. Según informa ICM Registry, empresa que se encarga provisionalmente de la venta de este dominio, ya han sido reservados más de 350000 y cada día se suman más empresas del sector que están dispuestas a pagar una alta suma anual por alojar sus sitios con una url tan ‘sexy’.
ICANN (organismo sin ánimo de lucro que regula la existencia de dominios de Internet) se topó con muchos problemas y controversias a la hora de aprobar el nacimiento de los .xxx.
Se opusieron a este dominio organizaciones religiosas y gobiernos de muchos países que consideraban esta medida como un estímulo para que nacieran más páginas relacionadas con el comercio del sexo, pero además contó con el rechazo de una parte de la industria del porno en EEUU, agrupada en la asociación Free Speech Coalition, quienes criticaban que con este modelo serían más facilmente castigados con la censura. Esta oposición consiguió retrasar siete años su puesta en marcha.
Por otra parte, el hecho de que las perspectivas económicas de la gestión de estos dominios es enorme, ha provocado numerosas críticas sobre el ‘monopolio’ de ICM Registry (quien tiene por el momento este privilegio por haber sido la impulsora del dominio) y hace prever que pronto se inicie una lucha legal por su control.
Fuente: Mangas Verdes
Spam-IP y su honeypot para Spammers
Spam-IP.com es un sitio web dedicado a informar y luchar contra el spam.En su labor de lucha se dedican a mantener una lista de IPs actualizada cada hora que han sido detectadas enviando spam para que puedan ser incluidas en listas negras, y que distribuyen en formato CSV para su procesado o vía web.
Una de sus fuentes de datos principales es la propia colaboración de los usuarios, que mediante este formulario pueden publicar IPs en la lista.La otra fuente es de lo más curiosa e innovadora.El principio es simple. El comportamiento de los spambots es recorrer internet constantemente en busca de formularios para enviar su spam.
En Spam-IP han creado un Honeypot que se trata de un formulario cualquiera como los de blogs, páginas de contacto, etc. Cuando un bot envía información en dicho formulario, su IP es automaticamente incluida en la lista.
Por supuesto, si es un usuario normal el que envía información en el formulario, su propia IP quedará incluida en la lista, por lo que NO hay que interactuar con el honeypot.
Una forma de ayudar al proyecto es incluir un enlace al Honeypot en nuestro sitio web, de forma que el enlace será seguido por los spambots y éstos podrán ser incluidos en la lista. Cuanto mayor sea el número de enlaces a la dirección en internet, mayor será la llegada de bots y por lo tanto mayor será la lista de IPs.
Fuente: Secure by DEFAULT
Bajo licencia Creative Commons
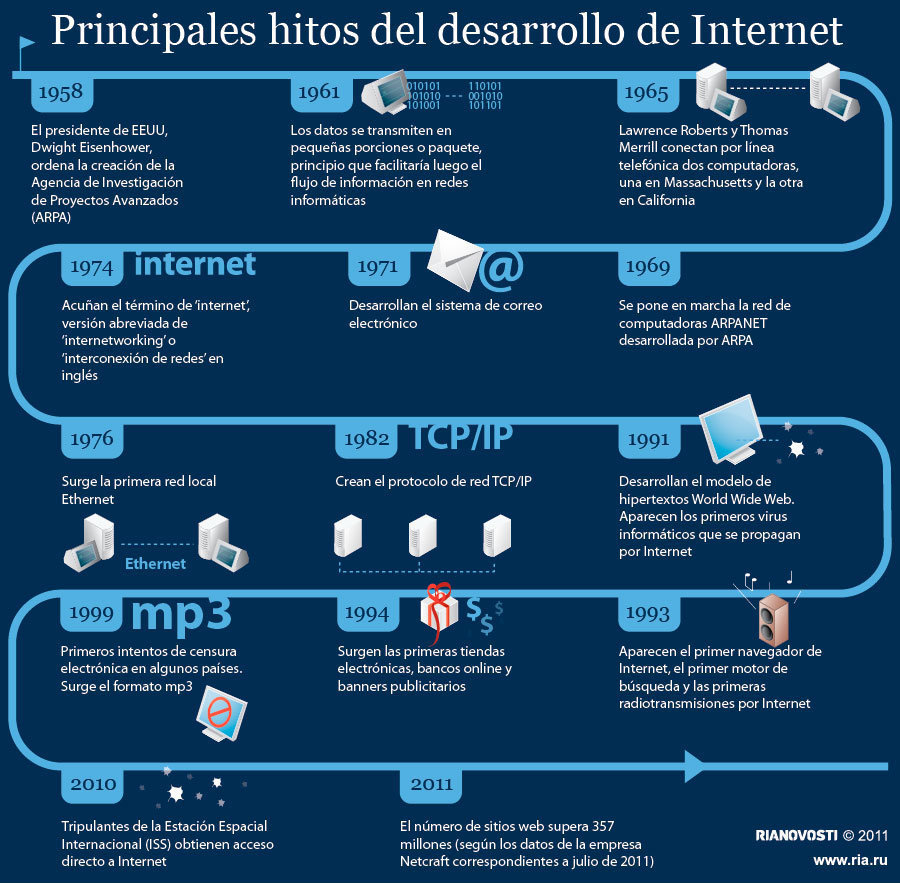
Hace 20 años se publicó el primer sitio web

Puede resultar curioso pensar en internet antes de la web, pero en algún momento ambas cosas no eran sinónimos y había que acceder a través de comandos a los contenidos que estaban en algún servidor en alguna parte. Ahora casi todo se puede hacer a través del navegador, un proceso que comenzó hace 20 años.
El seis de agosto de 1991 nació la World Wide Web, cuando el físico, de 36 años, Tim Berners-Lee, publicó el primer sitio web del mundo. Berners-Lee trabajaba en el CERN, y el sitio que creó estaba bajo el alero del centro de investigación.
Info.cern.ch era la dirección del primer sitio web y el primer servidor, corriendo en un computador NeXT en el CERN. La dirección de la primera página era http://info.cern.ch/hypertext/WWW/TheProject.html, que estaba centrada en información sobre el proyecto WWW. Los visitantes podían aprender sobre hipertexto, detalles técnicos para crear sus propias webs, e incluso explicaciones sobre cómo buscar información dentro de la página. No hay pantallazos de la página original, y en todo caso, los cambios a la información disponible se hacían todos los días, a medida que el proyecto WWW se desarrollaba.
En ese momento las únicas personas que surfeaban la (muy limitada) web, eran Berners-Lee y sus colegas científicos en el CERN, mientras el resto del mundo se mantenía en la ignorancia sobre lo que acababa de nacer ahí. De a poco, con la instalación de más servidores y la aparición de los navegadores, la web empezó a masificarse. El gran paso se dio en 1993, con el lanzamiento del navegador Mosaic, que ayudó inmensamente a popularizar la web.
En 1994, Berners-Lee fundó el World Wide Web Consortium (también conocido como W3C) en el Massachusetts Institute of Technology (MIT) para crear un estándar que permitiera que los sitios funcionaran de la misma manera – problema que se sigue resolviendo hoy con sistemas como el HTML5 por ejemplo. Berners-Lee sigue siendo el director del organismo, que ha guiado la formación de la web como la conocemos hoy.
Fuente: FayerWayer
Bajo licencia Creative Commons
Facebook y Twitter están creando una generación de autoobsesionados
Facebook y Twitter han creado una generación obsesionada con ellos mismos, personas que tienen poca capacidad de atención y el deseo infantil de difundir información constante sobre su vida, según las afirmaciones de un importante científico.
La exposición repetida a los sitios de redes sociales deja a los usuarios con una «crisis de identidad», reclamando su atención en la forma de un niño diciendo: «¡Mírame, mamá, he hecho esto.
Baroness Greenfield, profesor de farmacología en la Universidad de Oxford, cree que el crecimiento de las «amistades» de internet, – así como un mayor uso de los juegos de ordenador – puede efectivamente «recablear» el cerebro.
Esto puede dar lugar a disminución de la concentración, necesidad de gratificación instantánea y pocas habilidades no verbales, tales como la capacidad de hacer contacto visual durante las conversaciones.
Más de 750 millones de personas en todo el mundo usan Facebook para compartir fotografías y vídeos y publicar actualizaciones regulares de sus movimientos y pensamientos.
Millones de personas también se han adherido a Twitter, el servicio de ‘micro-blogging «que permite a los miembros enviar mensajes cortos de texto y mensajes con imágenes de sí mismos. Greenfield, exdirector del organismo de investigación de la Royal Institution, dijo: «Lo que me preocupa es la banalidad de lo mucho que sale en Twitter.
«¿Por qué alguien se interesa en lo que alguien ha consumido en el desayuno? Me recuerda a un niño pequeño (diciendo): «Mírame a mí, mamá, estoy haciendo esto», «Mírame a mí mamá que estoy haciendo eso». «Es casi como si estuvieran en una especie de crisis de identidad. En cierto sentido es mantener el cerebro en una especie de túnel del tiempo «.
El académico sugirió que algunos usuarios de Facebook sienten la necesidad de ser «minifamosos ‘, que son vistos y admirados por los demás a diario. Hacen cosas que son «dignas de Facebook», porque la única manera que pueden definirse a sí mismos es «que la gente sepa acerca de ellos».
«Es casi como si la gente está viviendo en un mundo que no es un mundo real, sino un mundo donde lo que cuenta es lo que la gente piensa de usted o (si) puede hacer clic en usted.» «Piense en las implicaciones para la sociedad si las personas se preocupan más de lo que otros piensan acerca de ellos que lo que ellos piensan sobre sí mismos.»
Sus opiniones recibieron eco por parte de Sue Palmer, un experto en la alfabetización, quien dijo que las niñas, en particular, creen que son una «mercancía que se debe vender a otras personas en Facebook».
Afirmó: «La gente solía tener un retrato pintado, pero ahora podemos estar más o menos en línea con el diseñode nuestra propia imagen. Es como ser la estrella de su propio reality show que se crea y pone a la vista de todo el mundo. «
Según un estudio realizado en Canadá, los usuarios de Internet Explorer son los más tontos
 Firefox 4 arrasó a Internet Explorer 9 en descargas el primer día, y de hecho, el navegador de Mozilla está ganando terreno al de Microsoft (gracias a que Chrome le está ‘robando’ usuarios, principalmente). Lo que nunca se había estudiado es la relación entre la elección de navegador y la inteligencia.
Firefox 4 arrasó a Internet Explorer 9 en descargas el primer día, y de hecho, el navegador de Mozilla está ganando terreno al de Microsoft (gracias a que Chrome le está ‘robando’ usuarios, principalmente). Lo que nunca se había estudiado es la relación entre la elección de navegador y la inteligencia.
Según un estudio de AptiQuant (en formato PDF), los usuarios de las versiones 6, 7, 8 y 9 de Internet Explorer tienen un cociente intelectual (IQ, por sus siglas en inglés) por debajo de la media, que está en 100 puntos. En concreto, los usuarios de IE 6 apenas superan los 80 puntos.
En AptiQuant llegaron a esta polémica conclusión después de analizar los resultados de 100000 exámenes de cociente intelectual (en concreto, un test Wechsler Adult Intelligence Scale o WAIS) realizados a personas de países de habla inglesa a lo largo de cuatro semanas.
“Teníamos la hipótesis de que la elección del navegador web está relacionada con la habilidad cognitiva de un individuo”, explican en el estudio. Por ello, decidieron hacer esta prueba.
Los más inteligentes, siempre según el estudio, son los usuarios de Opera, Camino e Internet Explorer con un marco de Chrome, que superan los 120 puntos.
Por otro lado, apenas hay diferencias entre quienes navegan utilizando Firefox, Chrome y Safari (todos se sitúan entre los 100 y los 110 puntos).
{kind=link}
Ampliar información en TICbeat

autobus las palmas aeropuerto cetona de frambuesa