Actualidad informática
Noticias y novedades sobre informática
Cinco mitos acerca Big Data

Con la cantidad de expectación en torno a Big Data es fácil olvidar que sólo estamos en los inicios. Más de tres exabytes de datos nuevos se crean cada día, y la firma de investigación IDC estima que 1200 exabytes de datos se generarán este año.
La expansión de los datos digitales se ha prolongado durante más de una década y para aquellos que han hecho un poco de investigación, entienden que las referencias de grandes cantidades de datos son mucho más que Google, eBay o Amazon y medianas series de datos. La oportunidad para una empresa de cualquier tamaño para obtener ventajas a partir de Big Data se deriva de la agregación de datos, extracción de datos y metadatos – los bloques de construcción fundamentales para el análisis de los negocios del mañana. En conjunto, estos datos ofrecen una oportunidad sin precedentes.
Sin embargo, a pesar de la amplitud de Big Data que se está discutiendo, parece que todavía es un misterio muy grande para muchos. De hecho, fuera de los expertos que tienen un gran dominio de este tema, los malentendidos en torno a Big Data parecen haber llegado a proporciones míticas.
Éstos son los cinco mitos:
1. Big Data es sólo volumen masivo de datos
El volumen es sólo un elemento clave en la definición de Big Data, y es posiblemente el menos importante de los tres elementos. Los otros dos son la variedad y la velocidad. En conjunto, estas tres «V» de Big Data se postularon inicialmente por Doug Laney de Gartner en un informe de 2001.
En términos generales, los expertos consideran petabytes de volúmenes de datos como punto de partida para Big Data, aunque este indicador de volumen es un blanco móvil. Por lo tanto, mientras que el volumen es importante, las dos siguientes «V» son mejores indicadores individuales.
Variedad se refiere a datos de muchos tipos diferentes de archivos que son importantes para gestionar y analizar más a fondo, pero para los que las bases de datos relacionales tradicionales se adaptan mal. Algunos ejemplos de esta variedad incluyen los archivos de sonido, películas, imágenes, documentos, datos de localización geográfica, registros web y cadenas de texto.
La velocidad es la tasa de cambio en los datos y la rapidez con que se deben utilizar para crear valor real. Las tecnologías tradicionales son especialmente poco adecuadas para el almacenamiento y el uso de alta velocidad de los datos. Por lo tanto se necesitan nuevos enfoques. Si los datos en cuestión se crean y se agregan muy rápidamente se deben utilizar con rapidez para descubrir patrones y problemas, cuanto mayor es la velocidad es más probable que se tenga una oportunidad para Big Data.
2. Big Data significa Hadoop
Hadoop Apache es el marco de software de código abierto para trabajar con Big Data. Fue derivado de tecnología de Google y llevado a la práctica por Yahoo y otros. Sin embargo, Big Data es muy variada y compleja, para única solución para todo. Aunque sin duda Hadoop ha logrado el reconocimiento y gran renombre, es sólo una de las tres clases de tecnologías muy apropiadas para el almacenamiento y la gestión de Big Data. Las otras dos clases son NoSQL y procesamiento masivo paralelo (MPP). Ejemplos de MPP Big Data son Greenplum EMC, IBM Netezza, y Vertica de HP.
Además, Hadoop es un marco de software, lo que significa que incluye una serie de componentes que fueron diseñados específicamente para resolver en gran escala el almacenamiento distribuido de datos, análisis y tareas de recuperación. No todos los componentes Hadoop son necesarios para una solución Big Data, y algunos de estos componentes pueden ser sustituido por otras tecnologías que complementan mejor las necesidades de un usuario. Un ejemplo es la distribución de Hadoop MAPR, que incluye NFS como una alternativa a HDFS, y ofrece un completo acceso aleatorio, de lectura/escritura del sistema de archivos.
3. Big Data significa datos no estructurados
El término «estructurado» es impreciso y no tiene en cuenta las muchas y sutiles estructuras típicamente asociadas con los tipos de Big Data. Además, los Big Data bien pueden tener diferentes tipos de datos dentro del mismo conjunto que no contienen la misma estructura.
Por lo tanto, Big Data es, probablemente, mejor llamado «multi-estructurado», ya que podría incluir cadenas de texto, documentos de todo tipo, archivos de audio y vídeo, metadatos, páginas web, mensajes de correo electrónico, feed de medios sociales de comunicación, datos de formularios, y así sucesivamente. El rasgo común de estos tipos de datos variados es que el esquema de datos no es conocido o se define cuando los datos se capturan y se almacenan. Más bien, un modelo de datos se aplica a menudo a la vez que se utilizan los datos.
4. Big Data es para feeds de medios de comunicación social y análisis de sentimiento
En pocas palabras, si una organización necesita analizar el tráfico web en términos generales, registros del sistema de TI, sentimiento del cliente, o cualquier otro tipo de datos digitales, que se están creando en volúmenes récord cada día, Big Data ofrece una manera de hacer esto. A pesar de que los pioneros de Big Data han sido los más grandes, basadas en la Web, las compañías de medios sociales -Google, Yahoo, Facebook- que era el volumen, variedad y velocidad de los datos generados por los servicios que requieren una solución radicalmente nueva en lugar de la necesidad de analizar feeds social o el sentimiento público de audiencias.
Ahora, gracias a la potencia de los ordenadores cada vez mayor (a menudo basados en la nube), software de código abierto (por ejemplo, la distribución de Apache Hadoop), y un tratamiento moderno de los datos que puedan generar valor económico si se utilizan adecuadamente, hay un sinfín de usos y aplicaciones Big Data. Un primer favorito y breve Big Data, que contiene algunos de los usos que hacen pensar, fue publicado como un artículo a principios de este año en la revista Forbes.
5. NoSQL significa No SQL
NoSQL significa «no sólo» SQL porque este tipo de bases de datos ofrecen acceso a un dominio específico y técnicas de consulta, de SQL o interfaces de tipo SQL. Tecnologías en esta categoría NoSQL incluyen bases de datos de claves, bases de datos orientados a documentos, bases de datos de gráficos, grandes estructuras planas, y almacenamiento en caché de bases de datos. Los métodos específicos de acceso nativo a los datos almacenados proporcionan un enfoque rico, de baja latencia, normalmente a través de una interfaz propietaria. El acceso SQL tiene la ventaja de familiaridad y compatibilidad con muchas herramientas existentes. Aunque esto es por lo general conlleva algún gasto de latencia impulsado por la interpretación de la consulta del «lenguaje nativo» del sistema subyacente.
Por ejemplo, Cassandra, la popular tienda de claves de código abierto valor ofrecido en forma comercial por DataStax, no sólo incluye las API nativas para el acceso directo a los datos de Cassandra, pero CQL (interfaz del tipo SQL) es su nuevo mecanismo de acceso preferido. Es importante elegir la tecnología NoSQL adecuada para satisfacer tanto el problema de negocio y tipo de datos y de las muchas categorías de tecnologías de NoSQL ofrecen un montón de opciones.
Fuente: Mashable business
![]()

Manera de probar aplicaciones informáticas en Ubuntu
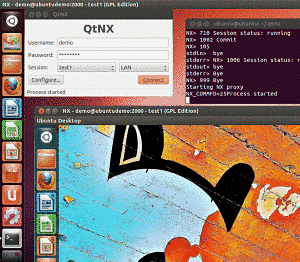
Qtnx es una interesante herramienta que viene por defecto en GNU Linux Ubuntu 12.04 y que se integra al Centro de Software. Su objetivo: probar aplicaciones desde el Centro de Software de Ubuntu sin necesidad de instalarlas.
QTNX es un cliente para el escritorio remoto NX. Esta tecnología permite ejecutar programas desde un servidor remoto, por lo que no se necesita instalar nada en el ordenador en uso.
Es de notar que no todos los programas tienen esta opción, aunque los más populares sí la tienen. En caso de que aún no se tenga instalado, se puede hacer desde el Centro de Software o abrir un terminal y escribir (sólo a partir de Ubuntu 12.049:
sudo apt-get install qtnx
![]()
25 aniversario del formato gráfico GIF

El 15 de junio del año 1987 Compuserve brindo al mundo algo con diversión garantizada, en un archivo no más pesado de dos Mb (aunque puede variar dependiendo la duración de la animación). Los GIF’s (graphic interchange format), pequeñas animaciones que pueden traer tanta alegría, cumplen hoy sus 25 años de edad, 25 años alegrando y animando la vida de los usuarios.
GIF es un formato sin pérdida de calidad para imágenes con hasta 256 colores, limitados por una paleta restringida a este número de colores. Por ese motivo, con imágenes con más de 256 colores (profundidad de color superior a ocho), la imagen debe adaptarse reduciendo sus colores, produciendo la consecuente pérdida de calidad.
Unisys, propietario de la patente del algoritmo LZW que se utiliza en el formato GIF reclamó durante años el pago de regalías por su uso. Compuserve, al desarrollar el formato, no sabía que el algoritmo LZW estaba cubierto por una patente. Debido a esto, cualquier programa capaz de abrir o guardar archivos GIF comprimidos con LZW debía cumplir con sus exigencias. Es necesario recalcar que el formato GIF puede utilizar otros métodos de compresión no cubiertos por patentes, como el método Run-length encoding. El 20 de junio de 2003 expiró en Estados Unidos la patente por el algoritmo LZW.
![]()
El proyecto Sócrates permite ahorrar 160000 € a la Universidad de Murcia

Sócrates es una plataforma docente basada en software libre que surge en la Universidad de Murcia.
Este proyecto ha permitido a la Universidad ahorrar 160000 € en las licencias correspondientes a 400 puestos además de mejorar la impartición de contenidos por parte de los profesores, facilitar la organización de los contenidos docentes y realizar una gestión centralizada de los sistemas informáticos.
Sócrates es un proyecto realizado por el Vicerrectorado de Economía e Infraestructuras y el Vicerrectorado de Investigación, de la Universidad de Murcia, que trata de dar un servicio fundamentalmente al profesorado de la Universidad de Murcia. El proyecto surgió ante la necesidad de dar un soporte centralizado a las aulas y fue la “la punta de lanza” del “Plan Estratégico de Introducción al Software Libre de la Universidad de Murcia” aprobado allá por el año 2004.
La solución Sócrates
Con Sócrates se solucionaban mucho aspectos como cierta dispersión existente en la gestión de los ordenadores de los diferentes centros, la no atención a determinados ordenadores, virus, sistemas operativos que se desconfiguraban, etc. Además este proyecto permitía dar un soporte informático cada vez más necesario en aulas de docencia presencial mediante presentaciones, internet, etc, de forma centralizada.
El servicio consiste en la disponibilidad de espacio en discos remotos para alojar información, principalmente de naturaleza académica de investigación y administrativa relativa a la Universidad. Se han habilitado aulas con PCs, monitores táctiles, pizarras digitales interactivas y proyectores, desde dónde se puede hacer uso de los discos remotos Sócrates.
La idea no es otra, que facilitar la movilidad del profesorado, de tal forma que pueda trabajar de forma cómoda y flexible utilizando contenidos multimedia en cualquier aula. Esto facilita enormemente la enseñanza y aporta un plus a la docencia de calidad. Mediante Sócrates, cualquier miembro de la Comunidad Universitaria puede disfrurar de 1GB de memoria en disco, al cual puede acceder, una vez dado de alta en el servicio.
Sócrates, software libre
Por la naturaleza libre del proyecto, este es extensible a cualquier ámbito docente tanto universitario como escolar y teniendo en cuenta el éxito del proyecto es más que posible su implantación en otras comunidades universitarias. Al estar basado en código abierto es posible adaptarlo a las necesidades de cada institución.
Se puede obtener más información además de una versión Live del Sistema Sócrates en la dirección siguiente: www.um.es/atica/socrates
![]()
Sobre el concepto “Nivel de Madurez”
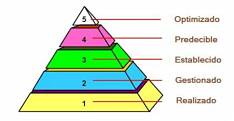
1 – Los niveles de madurez NO nacieron en el mundo del software. Fue mucho antes. El creador del concepto de “nivel de madurez” fue Crosby. El gurú de la calidad Crosby, que no tenía nada que ver con el desarrollo software, escribió un libro llamado “Quality is free” (la calidad es gratis), en el que aparecía el “Quality Management Maturity Grid (QMMG)”, con cinco niveles de madurez y que servía para evaluar los procesos de una organización. Posteriormente, sería Humphrey quien aplicaría esta idea al software (en “Characterizing the Software Process: A Maturity Framework” (1987)). Después Mark Paulk escribiría el CMM.
2 – El artículo donde por primera vez apareció el concepto de “nivel de madurez” aplicado al software es uno de los artículos más citados de la historia de la ingeniería software. Con motivo de su 25 aniversario, la revista IEEE Software recopiló sus artículos más citados, y en cuarta posición estaba el de Mark Paulk et al., “Capability Maturity Model, Version 1.1” (vol. 10, no. 4, 1993, pp. 18–27). Mark Paulk, excelente profesional y persona, con el que tuve la suerte de trabajar, y de conocer, al hacer con él mi estancia postdoctoral.
3 – Hoy hay ya decenas de campos dentro de la ingeniería del software que utilizan el concepto de nivel de madurez (incluido el mundo ágil). Los niveles de madurez no sólo existen el famoso CMMI. No sólo es la ISO 15504 parte 7 la que también utiliza niveles de madurez. Desde su aparición han aparecido múltiples Modelos de Madurez (*MM): QualiPSo Open Source Maturity Model (OMM), de aplicación al software libre, A Competency-Based Maturity Model, para la aplicación de ITIL, Outsourcing Management Maturity Model (OMMM), de aplicación en la externalización, Test Maturity Model Integration (TMMi), pruebas, Architecture Capability Maturity Model (ACMM), para arquitectura, y… un Agile Maturity Model (AMM).
Fuente: Javier Garzás
![]()
El lenguaje de programación no está protegido por derechos de autor, según el Tribunal de la UE

La sentencia se refiere a la demanda presentada por la empresa SAS Institute Inc contra la sociedad World Programming Ltd (WPL) por haber copiado los manuales y los componentes del sistema SAS, infringiendo a su juicio los derechos de autor y la licencia de la versión de aprendizaje.
El Tribunal británico preguntó al Tribunal de Justicia sobre el alcance de legislación europea que regula los programas de ordenador. La sentencia concluye que ni la funcionalidad de un programa de ordenador ni el lenguaje de programación o el formato de los archivos de datos constituyen una forma de expresión, por lo que no disfrutan de la protección de los derechos de autor.
El titular de los derechos de autor de un programa de ordenador no puede impedir que el adquirente de una licencia observe, estudie y verifique el funcionamiento de ese programa ni los actos de carga y desarrollo necesarios para su utilización, siempre y cuando no se infrinjan los derechos exclusivos del primero.
No puede haber infracción del derecho de autor cuando el adquirente de la licencia no ha tenido acceso al código fuente del programa de ordenador, precisa la sentencia.
No obstante, el Tribunal declara que la reproducción, en un programa de ordenador o en un manual de utilización, de elementos descritos en el manual de otro programa, puede infringir los derechos de autor. Pero sólo en el caso de que esa reproducción exprese la creación intelectual del creador del manual. Sin embargo, corresponde al órgano nacional verificar si esa reproducción es la expresión de la creación intelectual del autor del manual de uso del programa de ordenador, señala la sentencia.
Ampliar en: 20Minutos.es
bajo licencia Creative Commons
![]()
ISO 29119, la futura norma para pruebas de software

El objetivo de la norma ISO / IEC 29119, aún en elaboración, es crear un estándar definitivo sobre pruebas software, que recoja y estandarice el vocabulario, los procesos, técnicas de documentación, etc., del ciclo de vida de las pruebas.
La norma ISO 29119, por el momento, se ha estructurado en cuatro partes
Como es típico en muchas normas ISO, la ISO 29119 se ha dividido en varias partes (es decir, en varios documentos). Por el momento, estás son las cuatro partes en las que se está trabajando:
– Parte 1: Definiciones y Vocabulario.
– Parte 2: Proceso de Pruebas.
– Parte 3: Documentación de Pruebas.
– Parte 4: Técnicas de Pruebas.
La norma ISO 29119 unificará muchas otras normas relacionadas con el testing
La idea es que la ISO 29119 unifique unas cuantas normas previas, principalmente:
– La BS 7925-1.
– Las IEEE Std. 829, Software Test Documentation, IEEE Std 1008, Software Unit Testing, IEEE Std 1012-1998 Software Verification and Validation y IEEE Std 1028-1997 Software Reviews.
– Y varias ISO, como son la ISO/IEC 12207, Software Life Cycle Processes, ISO/IEC 15289, System and Software Life Cycle Process Information Products y ISO/IEC TR 19759, Guide to the Software Engineering Body of Knowledge.
Ampliar en: Javier Garzás, sobre calidad software y otros temas relacionados
![]()
Software de simulación optimiza las redes eléctricas
Casi todos los inviernos, las noticias sobre la reducción de los suministros de gas desde Siberia a Europa, aparece en los titulares. Independientemente de las razones políticas de la escasez, la gestión de las tuberías en los inviernos severos es muy difícil. Debido a que si el gas en los tubos se enfría demasiado bruscamente, en parte se licúa y puede no fluir rápidamente. Para mantener la temperatura de los gases dentro de un cierto rango consistentemente, un complejo sistema de compresores, precalentadores, enfriadores y otros elementos se necesita. Los operadores de sistemas hacen el seguimiento constante de la condición de sus tuberías y planificar el futuro de las reacciones a la temperatura potencial y los cambios de presión.Este software de simulación, llamado MYNTS (Multiphysical Network Simulation Framework), ayuda con la operación y planificación de las redes complejas, y ha sido desarrollado conjuntamente por el Instituto Fraunhofer de Algoritmos y Computación Científica SCAI y el equipo del profesor de matemáticas Dr. Caren Tischendorf de la Universidad de Colonia. Los modelos programan las redes de transporte así como los sistemas de ecuaciones diferenciales algebraicas. Así, a través de simulaciones numéricas, las redes pueden ser flexibles analizado y planeado mejor. Específicamente, la simulación inmediatamente demuestra los efectos de cambios en varios factores. Usando MYNTS, por ejemplo, se puede calcular cómo las fluctuaciones de temperatura alteran las mediciones de flujo, o cómo el fracaso de subredes influye en los componentes de otros.Planificación flexible de las redes de gas, electricidad y agua
«A pesar de tratar con los sistemas de transporte para los circuitos de gas, electricidad o agua, la simulación siempre se remonta a la base numérica misma», explica el jefe del departamento de Tanja Clees. Sin embargo, debido a que cada campo de aplicación también tiene sus características únicas, versiones especializadas del software están disponibles para diversas utilidades. Con MYNTS para la simulación de sistemas de transporte de gas, por ejemplo, un usuario puede configurar y controlar su propias subredes o añadir estaciones de compresión y las cámaras de mezcla. Con el fin de acelerar los cálculos de simulación, el software se ejecuta en ordenadores con varios procesadores.
Este software también es de interés para las redes inteligentes, la construcción que en los próximos años estará siendo promovida por el gobierno alemán. Debido a la creación de redes inteligentes y el control de los productores de electricidad, instalaciones de almacenamiento, los consumidores de electricidad y recursos de red dentro de las redes de suministro son consideradas como uno de los mayores retos económicos y ambientales de la tecnología.
Por ejemplo: si los consumidores a granel puede ser controlados de manera más eficiente, y la fuente de alimentación ajustada para satisfacer la demanda en momentos diferentes, entonces los picos de consumo podrían ser un límite, y el consumo de energía eléctrica iguala a la oferta. Estos consumidores son las empresas de agua a granel. Un estudio muestra que en los países industrializados, aproximadamente el tres por ciento del total de energía eléctrica consumida es utilizada por las empresas de agua – especialmente para las bombas. El control inteligente de la red que tienen un potencial económico importante: incluso los ahorros adicionales de menor importancia hacen una importante contribución a los beneficios al medio ambiente.
Clees y su equipo han sido capaces de demostrar la utilización con éxito de MYNTS en varios proyectos de investigación, y ahora comienzan los primeros proyectos comerciales. Las negociaciones para la concesión de licencias del software están actualmente en curso con las empresas en diversas industrias.
![]()
Munich ha ahorrado cuatro millones de euros al pasar sus sistemas informáticos a software libre

En el año 2003 se aprobó en Múnich el proyecto LiMux para la migración de las estaciones de trabajo en las dependencias municipales de la ciudad pasando de Windows a Linux. En el 2006 comenzó esa migración que hoy y según el alcalde de la ciudad, responde con unos números y cifras de ahorro realmente espectaculares. Según el político, se han ahorrado hasta cuatro millones de dólares al cambiar las infraestructuras ITde Windows NT y Office a Linux y OpenOffice.
Tal y como informa, la ciudad ahorró unos 2,8 millones en licencias de software y 1,2 millones de euros en hardware ya que las exigencias son menores para Linux en comparación con la implementación de Windows 7.
Todo gracias al proyecto conocido como LiMux con el que se han alcanzado cifras de ahorro de alrededor de un tercio de su gasto en el sector IT, especialmente en el coste de las licencias, descendiendo también el número de incidencias con una media al mes de 70 a 46.
Cifras espectaculares que también han visto un efecto en el propio empleo de la ciudad. La migración ha supuesto un aumento de 1 500 a 95 000 puestos de trabajo.
Hablando sólo de las licencias, el alcalde ha explicado que el cálculo de costes ahorrados es espectacular teniendo en cuenta que anteriormente existían 15 000 licencias de Microsoft Office y 7 500 licencias de Windows, lo que hubiera significado la compra en el tiempo de otros 7 500 equipos para cumplir con los requisitos del sistema de las versiones actuales de Windows.
La última comparación la realiza incluyendo los costes de capacitación y los costes de la migración. Para llegar a un nivel comparable a la situación actual de LiMux, el número de equipos nuevos aumentaría a 10 000, unas cifras de actualización en Windows de unos 15 millones de euros.
Fuente: ALT1040
Bajo licencia Creative Commons
![]()

autobus las palmas aeropuerto cetona de frambuesa