Actualidad informática
Noticias y novedades sobre informática
La encuesta del millón de muertes

La muerte en La India es un asunto privado. El epidemiólogo Prabhat Jha y otros investigadores llevan años luchando porque la situación cambie y los millones de muertes que se producen en el país, muchas en remotas aldeas, aparezcan en algún registro público. Un programa estatal bautizado como el Estudio del Millón de Muertes (Million Death Study) pretende documentar las muertes producidas entre 1997 y 2013 mediante encuestas personales a un millón de individuos. Hasta el momento llevan realizadas 450000 y los primeros datos están sirviendo para trazar un mapa de la mortalidad en el país que ya se está utilizando para cambiar la política sanitaria.
Tal y como explican en Nature, cuando tenía solo diez años el propio Prabhat Jha vivió la experiencia de la ‘muerte anónima’. Él y su familia vivían en Canadá cuando recibieron la noticia de que su abuelo había muerto en La India. La causa no estaba clara y, como sucede de forma habitual, el anciano había muerto en su casa, sin visitar ningún hospital. La madre de Jha regresó a la aldea en busca de información, pero no averiguó nada. Años más tarde, cuando Jha se hizo médico, revisó las notas de su madre y llegó a la conclusión de que su abuelo había muerto por un infarto cerebral, aunque la causa de la muerte nunca constará en los archivos públicos ni en ninguna estadística.
Los esfuerzos por documentar las causas de las muertes están dando sus primeros frutos. La revista Nature publicaba hace unos días una serie de gráficos ilustrando los niveles de incidencia de distintas enfermedades por regiones. El proceso consiste en la visita sobre el terreno de unos 900 encuestadores que acuden a distintos lugares del país para preguntar por la causa de muertes no registradas. Con los datos obtenidos, dos médicos analizan cada caso y concluyen esta denominada “autopsia verbal” que determina la causa de la muerte.
El sistema alternativo que se propone consiste en introducir los síntomas en un programa matemático y determinar conforme al modelo estadístico cuál es la afectación real de la enfermedad. Algunos estudios apuntan que los ordenadores pueden ser más precisos que los propios médicos a la hora de determinar cuál ha sido la causa de una enfermedad, y ya se está utilizando un modelo mixto en casos como el programa INDEPTH, que registra los nacimientos y muertes en 17 países africanos y asiáticos con un modelo probabilístico y verbal a la vez. El objetivo, en cualquier caso, es acercarse lo más posible a la realidad para poder determinar de qué muere la gente, cómo se extienden las enfermedades y qué medidas se pueden tomar para atajarlas.
Referencias: Global health: One million deaths (Nature) | Verbal autopsy methods questioned (Nature) | Más info: Million Death Study
Artículo completo en: CUADERNO DE CULTURA CIENTÍFICA
![]()

El juego de la vida, versión estratégica

Thomas Hunter ha creado The Strategic Game of Life que es una versión del famoso juego de autómatas celulares en el que hay que lograr objetivos, concretamente dibujar el estado inicial de las celdas dentro del área naranja para «llegar» a absorber la celda coloreada en azul. Se pueden preparar deslizadores, láseres y otras estructuras complejas o dejar las cosas medio al azar a ver qué pasa cuando se pulse el Play. Interesante entretenimiento.
Fuente: microsiervos
![]()
Sistema de reconocimiento de voz

La tecnología de reconocimiento de voz no nació con el Apple iPhone 4s- el primero en el que apareció Siri. La atención telefónica lleva utilizando esta forma de interacción muchos años. Y no deja de ser un reflejo de la mejora de la técnica el que la máquina antes entendiera al humano de pascuas a ramos mientras que ahora la precisión ha aumentado. Éste es el método tradicional, el de los comandos de voz.
Hoy día se está acompañando a estos comandos de una capa de lenguaje natural. Así lo expresa Marco A. Piña Sánchez, director de ventas de empresa y movilidad para Iberia de Nuance, una compañía que proporciona reconocimiento de voz al smartwatch de Samsung, Galaxy Gear, al Galaxy Note III y también está presente en Siri. “En vez de decir ‘tarjeta’ o decir ‘saldo’ se puede decir directamente ‘quiero saber el saldo de mi cuenta que acaba en 23 y hacer una transferencia de 100 euros a la cuenta que acaba en 45’. Es decir, se está estableciendo una capa más de diálogo”, explica, aclarando que tras procesar el sonido, la máquina acude a la base de datos del banco en busca de la respuesta.
El reconocimiento de voz: capa a capa
Pero, ¿cómo es capaz el software de reconocer el habla? Un sistema de reconocimiento de voz está formado por varias capas o modelos, según señala Piña. El primero de ellos es el modelo acústico, que permite a la tecnología identificar si el sonido procede de una llamada de móvil, de un teléfono IP o cualquier otro medio. Determinar el canal de comunicación es importante para establecer el grado de distorsión que puede experimentar el mensaje.
El modelo lingüístico va a continuación y se trata del idioma. Pero no es tan sencillo como indicar al sistema que reconozca castellano, francés o mandarín. “Nuestro software está perfectamente preparado para portugués, pero en ocasiones nuestra gente de servicios tiene que hacer algunas pequeñas modificaciones, por ejemplo para entender el portugués que se habla en Madeira, que puede tener algún giro especial”, comenta el directivo de Nuance. No sólo es preciso entender la lengua sino los distintos acentos con que se habla e incluso entender las formas de expresarse, que pueden ser diferentes en cada hablante.
Ésta es otra capa más: el modelo semántico. Con él se consigue que un sistema de reconocimiento de voz entienda la forma de hablar de la gente, cómo se construyen las frases y cómo puede variar esta construcción, dependiendo de la región, de la cultura y de todas las influencias personales de cada cual. Por último, funciona un motor estadístico, que recoge la frase una vez transcrita a texto y realiza una búsqueda en la base de datos con estos términos.
Esta consulta tiene que adivinar si la frase dicha, con el nivel de distorsión correspondiente si se habla desde un móvil, el acento y la forma de decirlo están pidiendo una determinada acción. La precisión del software al final se reduce a aumentar la base de datos para alcanzar todas las combinaciones posibles en un idioma. Es más, en cada nuevo entorno que se implementa hay que construir un nuevo modelo semántico.
“Ante un proyecto empresarial, lo primero que tenemos que hacer es saber cómo los clientes preguntan a esa compañía”, puntualiza Piña. “Llegará, pero todavía no estamos a un nivel de inteligencia artificial en el que yo pongo un software y, sea una telco, sea una financiera, una empresa de transportes o una textil, pueda entender cualquier cosa que yo le diga de ti”, señala.
Fuente: eldiario.es
Licencia CC
![]()


Almacenando millones de palabras para alcanzar la traducción automática perfecta

Los seres humanos siempre han soñado con máquinas para traducir las lenguas de los extranjeros, acaso como ese dispositivo tipo Star Trek que nos permitiría acceder a la comunicación universal. Latraducción automática, de hecho, ya fue un objetivo de los pioneros de la informática en la década de 1940, cuando los ordenadores ocupaban habitaciones enteras.
En 1954, combinando reglas gramaticales y un diccionario bilingüe, un ordenador de IBM tradujo 60 frases rusas al inglés. Concretamente usó 250 pares de palabras de vocabulario y 6 reglas gramaticales. Alguna de las frases que se tradujeron impecablemente fueron, por ejemplo, “Mi pyeryedayem mislyi posryedstvom ryechyi”. Tras el reverberar del IBM 701, por medio de tarjetas perforadas, salió: “Transmitimos pensamientos por medio del habla”.
El logro fue tan celebrado, resultó tan impresionante para todo el mundo, que al director del programa de investigación, Leon Dostert, no le dolieron prendas al pronosticar que en un plazo de cinco años, aproximadamente, la traducción automática constituiría un “hecho acabado.”
Sin embargo, con el transcurrir de los años, los expertos advirtieron que traducir automáticamente entrañaba más obstáculos de lo que parecía. El ordenador no sólo debe aprender las reglas, sino las excepciones; y la traducción no consiste sólo en memorizar y recordar, sino en usar la inteligencia para escoger las palabras correctas entre muchas opciones.
A partir de 1980, los investigadores empezaron a permitir que el ordenador usara la probabilidad estadística para calcular qué palabra o frase de un idioma en concreto era la más oportuna, además de tener en cuenta las reglas lingüísticas explícitas junto con un diccionario. En la década de 1990, el programa Candide de IBM usó el equivalente a 10 años de transcripciones de sesiones del Parlamento de Canadá publicadas en francés y en inglés: unos tres millones de pares de frases.
Empezaba, pues, un salto conceptual, una nueva era llamada traducción estadística automática, lo que permitió que las traducciones a través de un ordenador se volvieran mucho más precisas. Con todo, las buenas traducciones distaban mucho de producirse. Hasta 2006.
Artículo completo en: XATAKA Ciencia
![]()
Disponible la primera versión oficial del lenguaje de programación de Google, Dart 1.0

En 2011, Google comenzaba a presentar los primeros pasos de Dart, su lenguaje de programación orientada a objetos, que se sumaba a otro intento llamado Go. En octubre del año pasado llegaba el SDK oficial y hoy finalmente está disponible la versión 1.0 de Dart.
Dart es un lenguaje de programación que ya está listo para que los desarrolladores web comiencen a crear aplicaciones basadas en él, y para los más desprevenidos podemos decir que se trata de una propuesta que tiene mucho en común con JavaScript, lo mostraron con Dart Synonym.
En todo caso, y tal como nos lo cuentan los desarrolladores desde el sitio oficial de Dart, se trata de un lenguaje de programación que es sencillo pero potente a la vez, y que ofrece herramientas de trabajo muy robustas y bibliotecas estándar que ya están completas, elementos con los cuales podemos lograr un flujo de trabajo rápido y sin complicaciones, pero que además ofrezca buenos índices de escalabilidad para aquellos proyectos que crezcan. Además, se cuenta con Dart Editor, un IDE (entorno de desarrollo con autocompletado de código, refactoring, debugger, etc), con Dartium (una versión propia de Chromium para realizar las pruebas con su máquina virtual Dart incluída), con dart2js (un traductor de JavaScript) y con Pub (un gestor de paquetes).
Ya que hablamos de dart2js, decir que el traductor permite la ejecución de código Dart en toda clase de navegadores, y que el rendimiento obtenido es muy superior al que se lograba con el en las primeras versiones de Dart, con un código resultante que es un 40 por ciento más pequeño que hace un año atrás. A la par de esto, ya se ve la adopción de Dart en varias compañías de primer nivel como Adobe, drone.io y JetBrains, y en Google ya lo están utilizando para varios de sus proyectos más importantes, como Google Elections.
Fuente: VISUALBETA
![]()
Wolfram anuncia un nuevo lenguaje de programación

Stephen Wolfram, fundador del conocido buscador semántico Wolfram | Alpha, anuncia a través de su blog el desarrollo de un nuevo lenguaje de programación al que llamará Wolfram Language, el cual estará basado en la aplicación Mathematica, que lleva usando en su compañía durante más de 25 años. Según él, su lenguaje de programación tiene una visión diferente respecto a los diferentes lenguajes de programación de propósito general existentes, ya que pretende ser un único sistema totalmente integrado, integrando todo lo posible en el mismo lenguaje, con la idea de no depender de librerías externas para aumentar las funcionalidades, según informa The Verge.
De esta manera, contaría con capacidades para la creación de gráficos, procesamiento de imágenes, o incluso para la comprensión del lenguaje natural, entre otros, de manera que permitiría realizar tareas complejas mediante formas sencillas y fáciles de aprender. El lenguaje permitiría el desarrollo de aplicaciones de escritorio estándar, y la compañía del propio fundador también lanzará una nube para programación, que permitirá a los desarrolladores la creación y puesta en marcha de sus aplicaciones a través de la web.
Wolfram Language también traería avances en el software Mathematica, entre los que se incluye el lanzamiento de Mathematica Online, que permite la ejecución de sesiones completas dentro del propio navegador web.
Fuente: wwwhat’s new
![]()
Herramientas educativas en línea

C4LPT (Centre for Learning & Performance Technologies) ha compartido una nueva edición de los resultados arrojados por su encuesta anual sobre las 100 mejores herramientas para el Aprendizaje.
Una lista que tiene en cuenta tanto aquellas herramientas que contribuyen al desarrollo y formación del docente como las que influyen directamente en la forma de impartir la enseñanza. Esta iniciativa liderada por Jane Hart puede ser una guía interesante a tener en cuenta para implementar nuevos recursos y herramientas educativas. Dando un recorrido por los primeros puestos:
1. Twitter por cuarto año consecutivo sigue posicionándose entre las herramientas favoritas de los educadores. Por su simplicidad y nivel de interacción permite combinar diferentes iniciativas educativas. Podemos ver algunos ejemplos en Uso de Twitter en el mundo acádemico.
2. Google Drive combina múltiples herramientas y opciones que lo convierten en uno de los servicios online ideales para trabajar con proyectos educativos. Y si buscamos opciones similares, también encontraremos SkyDrive en la lista.
3.YouTube no solo es una fuente interesante de videos que podemos utilizar como parte de nuestro plan de estudio, sino que también cuenta con opciones que nos permiten potenciar su uso, como por ejemplo su editor, así como la integración de diferentes complementos como los que ya hemos comentando.
4. Google puede ser una potente herramienta si nos valemos de sus múltiples funciones de búsquedas y conocemos algunos atajos y trucos que nos pueden dirigir a la información que estamos buscando, como los que hemos compartido en este artículo.
5.Power Point ha sido escogida como una de las primeras opciones al momento de crear y compartir presentaciones. Pero también se han incluido otras herramientas para presentaciones como Prezi y Slideshare.
En la lista también se han mencionado herramientas de curaduría como por ejemplo Pinterest, Scoop.it, Flipboard, Zite, Storify. Además de Google, Wikipedia y Google Académico son las opciones favoritas entre las herramientas de búsquedas e investigación.
Por otro lado, las plataformas de educación online y afines también han tenido su lugar en esta recopilación, como Coursera, Edmodo, Moodle, KhanAcademy. Si buscamos herramientas de organización personal, nos encontramos con Evernote, OneNote. Entre las plataformas de blogging tenemos Blogger, WordPress y Tumblr.
Los Hangouts, Skype, GoToMeeting son algunas de las opciones que se presentan en herramientas para reuniones online y actividades afines. Y por supuesto, además de Twitter que hemos mencionado, Facebook, Google+ y LinkedIn se encuentran entre las redes sociales seleccionadas.
Podemos ver el resto de las herramientas online utilizadas con fines educativos, en la presentación que se comparte en C4LPT. Y también podemos consultar la selección de las 50 mejores herramientas online para profesores que compartimos en un artículo anterior.
Fuente: wwwhatsnew.com
![]()
Nuevo software que resuelve CAPTCHA
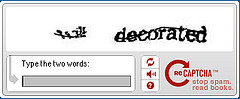
CAPTCHA, el método para distinguir humanos de robots usando textos distorsionados, ha sido crackeado por la compañía Vicarious. Su objetivo, sin embargo, no es usar el software de forma maliciosa ni siquiera venderlo, sino avanzar en la senda de una verdadera inteligencia artificial.
En 1950, Alan Turing publicó un artículo en la revista Mind en el que se preguntaba ¿Pueden pensar las máquinas? Para resolver la pregunta sin ambigüedad, propuso el famoso test de Turing: un examinador hace preguntas a dos individuos que se hallan en otra habitación y se comunican por teletipo (el método ideal en tiempos de Turing, hoy sería simplemente internet). ¿Qué sucedería si una máquina tomara el papel de uno de ellos? ¿Sería capaz el examinador de descubrir a la máquina?
La forma más popular de distinguir humanos de robots es un algoritmo desarrollado en 2000 por la Carnegie Mellon University llamado CAPTCHA. Sus siglas significan Test de Turing público completamente automatizado para distinguir entre humanos y ordenadores. Más de 100.000 sitios web usan el algoritmo para distinguir la inteligencia basada en carbón (animal) de la basada en silíceo (ordenadores).
CAPTCHA presenta un conjunto de letras distorsionadas que un humano reconoce y un robot no (he de confesar que en múltiples ocasiones las letras presentadas me han resultado tan complicadas que me ha producido una notable irritación pasar de una secuencia fallida a otra). En 2009, Google presentó reCAPTCHA, una versión del algoritmo que además de su propósito original, es uno de los mayores esfuerzos de crowdsourcing que se están llevando a cabo. Se utiliza para descifrar palabras ilegibles de libros digitalizados. reCAPTCHA presenta dos palabras: una es conocida por el software y la otra es un texto digitalizado de un libro en papel que el sistema OCR (reconocimiento óptico de caracteres) ha sido incapaz de reconocer. Si el usuario acierta con la palabra conocida, el sistema asume que también lo ha hecho con la desconocida que se da por buena. De este modo, todos contribuimos al reconocimiento de textos en libros digitalizados.
CAPTCHA ha resultado sumamente útil. La única forma de romperlo de forma masiva en la actualidad es contratar empresas de mano de obra barata que usan a personas. Empresas con personal en Bangladesh que rompen siete CAPTCHAs por minuto a 50 céntimos la hora.
Para considerar CAPTCHA batido, basta con resolverlo un 1% de las veces. Ahora, una empresa llamada Vicarious dice ser capaz de resolverlo un 90% de las veces. Según la compañía, su intención no erar resolver CAPTCHA sino avanzar en una inteligencia artificial más parecida a la humana y la resolución de CAPTCHA es un simple subproducto. No pretenden usarlo de forma fraudulenta sino que es una demostración de cómo sus algoritmos emulan el funcionamiento del cerebro y de hecho, esto es solo una parte del camino de la emulación cerebral.
Vicarious dice que sus métodos son incluso más impresionantes que el aprendizaje que mostró el famoso IBM Watson. Ellos tratan de encontrar las matemáticas que subyacen a los procesos cerebrales. Vicarious ha recibido 15 millones de dólares de inversores como Dustin Moskovitz, cofundador de Facebook o el ex CEO de PayPal Peter Thiel.
El software de Vicarious: emula la visión humana en lo que ellos llaman redes corticales recursivas. Una capa de nodos detecta pixels. La siguiente capa detecta una agrupación específica de pixeles. La siguiente capa detecta una parte de una forma concreta. El proceso se repite hasta en ocho capas y usa más de ocho millones de nodos. Pusieron a trabajar el software para resolver un problema concreto y el resultado es que han resuelto CAPTCHA.
Fuente: ALT1040
Licencia CC
![]()

autobus las palmas aeropuerto cetona de frambuesa