Actualidad informática
Noticias y novedades sobre informática
Espectacular portal interactivo de Google

Desde marzo del año 2009 Google, y en particular el equipo de desarrollo de Chrome aunque estaba abierto a desarrolladores externos, ha ido ampliando con nuevos desarrollos y ejemplos el portal denominado ChromeExperiments en donde se muestra lo que es capaz de conseguirse utilizando únicamente HTML5, Javascript y la tecnología implementada en muchos navegadores web como es WebGL y de la que Google es su máximo exponente.
Con la llegada a la cifra de 500 de estos “experimentos” el equipo de Chrome lo celebra con un nuevo experimento para agradecer a todos los participantes su esfuerzos por hacer estas tecnologías web más conocidas y difundirlas.
Este trabajo de agradecimiento es un gran número 500 interactivo en donde al pasar el ratón por encima se van mostrando todos los trabajos disponibles y pinchando en alguno de ellos nos lleva directamente a la ejecución de este.
Sitio ChromeExperiments
Fuente: actualidadg
Bajo licencia Creative Commons
![]()

Pediaclic un proyecto colaborativo de información sobre salud
![]()
PediaClic es un proyecto colaborativo en el que participan pediatras, médicos de familia y profesionales de la enfermería y la documentación biomédica, de España, México y Argentina.
La búsqueda de información fiable sobre salud infantil y juvenil es un reto constante. La «infoxicación», o intoxicación por exceso de información, es un problema de primera magnitud al que diariamente nos enfrentamos los profesionales sanitarios y también los padres.
En muchas ocasiones existe el problema añadido del idioma. El inglés se ha convertido, de alguna manera, en el «idioma oficial» de la medicina y otras ciencias de la salud relacionadas. La información relevante en otros idiomas del ámbito español y latinoamericano existe pero de algún modo suele ser más difícil de recuperar o bien no se le dala importancia que sin duda merece.
Para mitigar estos problemas nace PediaClic. PediaClic es una herramienta de búsqueda de recursos de información sanitaria infantojuvenil. Para su creación y desarrollo se ha utilizado la herramienta de búsqueda personalizada de Google.
PediaClic es un conjunto de buscadores personalizados de información sobre salud infantojuvenil. Se dirige tanto a profesionales sanitarios como a las familias. La información incluida en los diversos buscadores debe cumplir con estos criterios generales:
PediaClic está formado por un buscador general y diez buscadores específicos. El buscador general aparece en la página principal de PediaClic. Al realizar cualquier búsqueda, la información que se devuelve aparece clasificada por categorías, cada una de ellas correspondiente a un tipo de documento específico
Ampliar en: Pediatría Basada en Pruebas
Bajo una licencia de Creative Commons.
![]()
La tableta Google Nexus 7 ya está a la venta en España

El Nexus 7 ya está disponible en la tienda Google Play Store en Francia, Alemania y España. Los modelos de 8GB y 16GB están disponibles por € 199 y € 249 (respectivamente, IVA incluido). Google es el único vendedor del modelo de 8 GB así como del modelo de 16GB, que estará disponible en tiendas seleccionadas a partir del tres de septiembre.
Al igual que en otros países, la tableta viene con € 20 de crédito para comprar aplicaciones, películas y libros .en la tienda de aplicaciones de Google.
Sin embargo, en estos tres países, revistas y música todavía no están disponibles en la tienda de contenidos de Google. Hasta ahora, los escasos márgenes en el Nexus 7 son compensados por las compras de música, libros, revistas, películas y aplicaciones. Será más difícil de rastrear el beneficio de los tres países europeos.
Desde la liberación de la tableta la semana anterior, Google está tentando a los clientes a comprar la tableta a través de su tienda en línea con el fin de evitar los márgenes de comercialización. La tableta está ahora disponible en EE.UU., Canadá, Reino Unido, Australia, Francia, Alemania y España.
A pesar de que la tienda de juegos es incompleta en esos países, Google podría estar lanzando el Nexus 7 en Europa tan pronto como sea posible antes de una conferencia de prensa de Amazon el seis de septiembre, donde se espera un nuevo Kindle Fire, y una conferencia de Apple hipotéticamente a finales de septiembre o a principios de octubre, donde podría darse a conocer el Mini iPad.
Revisión de TechCrunch de Nexus 7.
![]()
«Cerebro artificial» de Google aprende a encontrar vídeos de gatos

Cuando científicos de computación en el misteriosa laboratorio X de Google elaboraron una red neuronal de 16000 procesadores de ordenador con mil millones de conexiones y dejaron que navegara por YouTube, hizo lo que muchos usuarios de internet podrían hacer -comenzó a buscar gatos.
El «cerebro» de simulación fue expuesto a 10 millones de selecciones al azar, miniaturas de los vídeos de YouTube en el transcurso de tres días y, después de haberle sido presentada una lista de 20000 artículos diferentes, comenzó a reconocer fotos de gatos mediante un algoritmo de «aprendizaje profundo». Esto fue a pesar de ser alimentado sin información sobre las características distintivas que podrían ayudar a identificar a uno.
Recogiendo las imágenes que aparecen más frecuentemente aparecen en YouTube, el sistema alcanzó 81,7 por ciento de exactitud en la detección de rostros humanos, 76.7 por ciento de exactitud en la identificación de partes del cuerpo humano y 74,8 por ciento de exactitud en la identificación de gatos.
«Al contrario de lo que parece ser una intuición muy extendida, nuestros resultados experimentales revelan que es posible entrenar a un detector de caras sin necesidad de etiquetar las imágenes que contiene una cara o no», dice el equipo en su artículo, Building high-level features using large scale unsupervised learning, que se ha presentado en la Conferencia Internacional sobre Aprendizaje Automático en Edimburgo, del 26 de junio al uno de julio.
«La red es sensible a los conceptos de alto nivel como las caras de gato y el cuerpo humano. A partir de estas características adquiridas, hemos entrenado a obtener el 15,8 por ciento de precisión en el reconocimiento de 20000 categorías de objetos, un salto de 70 por ciento de mejora relativa en el anterior estado de la última generación».
Los hallazgos, que podrían ser útiles en el desarrollo del habla y el software de reconocimiento de imagen, incluyendo servicios de traducción, son notablemente similares a la «célula abuela» la teoría que dice que ciertas neuronas humanas están programadas para identificar los objetos considerados significativos. La «neurona abuela» es una neurona que se activa hipotéticamente cada vez que experimenta un sonido o una visualización significativos. El concepto podría explicar cómo se aprende a discriminar entre identificar objetos y palabras. Es el proceso de aprendizaje a través de la repetición.
«Nunca se dijo durante el entrenamiento:» Este es un gato», Jeff Dean, quien dirigió el estudio, dijo al New York Times. «Básicamente, inventó el concepto de gato.»
«La idea es que en vez de tener equipos de investigadores que tratan de averiguar cómo encontrar límites, en su lugar lanzan un montón de datos en el algoritmo y dejan que los datos hablen y el software automáticamente aprender de los datos», añadió Andrew Ng , científico informático de la Universidad de Stanford involucrado en el proyecto. Ng ha sido desarrollador de algoritmos para el aprendizaje de datos de audio y visuales por varios años en Stanford.
Desde su llegada a la opinión pública en 2011, el laboratorio secreto de Google X – se cree que se ubica en el Área de la Bahía de California – ha publicado investigaciones en internet de cosas tales, un ascensor espacial y la conducción autónoma.
Su última aventura, aunque no llegando al número de neuronas en el cerebro humano (se cree que más de 80 millones de dólares), es uno de los simuladores cerebrales más avanzado del mundo. En 2009, IBM ha desarrollado un simulador del cerebro que reproducía mil millones de neuronas del cerebro humano conectadas por diez billones de sinapsis.
Sin embargo, la última oferta de Google parece ser el primero en identificar los objetos sin pistas e información adicional. La red continuó para identificar correctamente los objetos, incluso cuando se distorsionan o se colocan con fondos destinados a desorientar.
«Hasta ahora, la mayoría de los algoritmos [anteriores] sólo habían tenido éxito en el aprendizaje de bajo nivel, tales como detectores «bordes» o «manchas», dice el documento.
Sin embargo, Google se considera como un avance que la investigación ha hecho que el gran salto desde el laboratorio X para sus laboratorios principales.
![]()
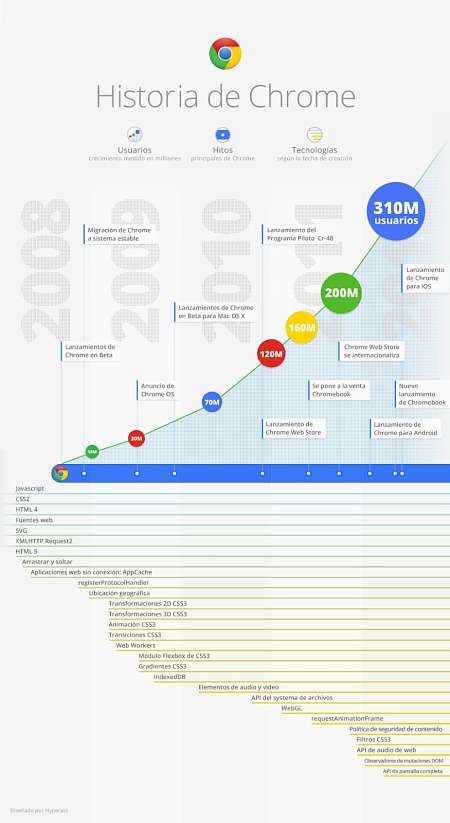
Algunas cifras sobre productos de Google

Días atrás Chrome superaba a Internet Explorer por primera vez en la historia como navegador más usado a nivel mundial, y hoy Google da varias cifras interesantes sobre la cantidad de usuarios de Chrome y otros de sus productos, como el recién lanzadoDrive, la Chrome Web Store y otros ya clásicos como Gmail.
- 310 son los millones de usuarios activos con los que cuenta Chrome. Cifra que casi dobla los 160 millones, la que se anunció el año pasado en la I/O, su conferencia anual de desarrolladores.
- 60 000 000 000 (60 mil millones) de palabras son tecleadas por día en el rectángulo vacío de la búsqueda de Chrome, algo así como si cada día se escribieran 100 000 libros. Qué difícil además cuantificar el enorme cambio que esto está produciendo en nuestra forma de buscar información en la web.
- 13 años diarios son los que ahorran los usuarios que utilizan la carga previa y Omnibox, la barra de direcciones que también es caja de búsquedas.
- 425 millones de personas usan activamente Gmail
- 10 millones de usuarios son los que tiene ya Google Drive a 10 semanas de su lanzamiento.
- 5 millones de empresas desarrollan su actividad en la nube con herramientas de Google.
- 42 es el número de países en los que está disponible la Chrome Web Store (bonito número ¿verdad?), y sus aplicaciones se han instalado más de 750 millones de veces.
Fuente: ALT1040
Bajo licencia Creative commons
![]()
Google conmemora el centenario del nacimiento de Alan Turing
Los Aliados ganaron la Segunda Guerra Mundial gracias al matemático Alan Turing. No ganó ninguna batalla, no empuñó un fusil ni dirigió un escuadrón, pero desde Bletchley Park (Reino Unido) lideró el proceso de decodificación del arma secreta de las comunicaciones alemanas: la máquina Enigma. Google le ha dedicado uno de sus doodle, los homenajes a personalidades o eventos con los que sustituye su habitual logotipo. Hoy podemos recrear online el funcionamiento de las llamadas Máquinas Turing.
![]()
Los ordenadores cuánticos podrían ayudar a los motores de búsqueda a seguir el ritmo de crecimiento de internet
Científicos de USC (University of Southern California ) demuestran que la computación cuántica podría acelerar la forma en que se calcula el ordenamiento por relevancia a través de una internet cada vez con mayor páginas web.
La mayoría de la gente no piensa dos veces acerca de cómo funcionan los buscadores de internet. Puede escribir una palabra o frase, pulsa enter, y una lista de páginas web aparece, organizada por relevancia.
Detrás de las escenas, hay muchas matemáticas que van a averiguar exactamente lo que califica como la mejor página web correspondiente a la búsqueda. Google, por ejemplo, utiliza un algoritmo de ranking de páginas que se rumorea que es el cálculo numérico más grande llevado a cabo en cualquier parte del mundo. Con la red en constante expansión, los investigadores de la USC han propuesto – y demostraron la viabilidad – de la utilización de los ordenadores cuánticos para acelerar ese proceso.
«Este trabajo es acerca de tratar de acelerar la forma en que se realiza la búsqueda por las webs«, dijo Daniel Lidar, autor principal de un artículo sobre la investigación que apareció en la revista Physical Review Letters el cuatro de junio. A medida que internet continúa creciendo, el tiempo y los recursos necesarios para ejecutar el cálculo – que se realiza todos los días – crece con ella, afirmó Lidar.
Lidar, que tiene colaboraciones en USC Viterbi School of Engineering y USC Dornsife College of Letters, Arts and Sciences,y el primer autor Dornsife Garnerone Silvano, un antiguo investigador postdoctoral en la USC y actualmente en la Universidad de Waterloo, para ver si la computación cuántica podría ser utilizada para ejecutar el algoritmo de Google más rápido.
A diferencia de los bits de un ordenador tradicionales, que se pueden codificar claramente ya sea un uno o un cero, los ordenadores cuánticos utilizan bits cuánticos o «cubits«, que se pueden codificar un uno y un cero al mismo tiempo. Esta propiedad, llamada superposición, algún día permitirá a los ordenadores cuánticos realizar ciertos cálculos mucho más rápidos que las computadoras tradicionales.
En la actualidad, no hay un ordenador cuántico en el mundo lo suficientemente grande como para ejecutar el algoritmo de Google para el ranking de las páginas en toda la Web. Para simularlo que una computadora cuántica podría realizar, los investigadores generaron modelos de web que simulan unos pocos miles de páginas web.
La simulación mostró que una computadora cuántica podría, en principio, devolver el ranking de las páginas más importantes en la Web más rápidamente que las computadoras tradicionales, y que este aumento de velocidad cuántica podría mejorar las páginas más necesarios para su clasificación. Además, los investigadores demostraron que para determinar simplemente si los rankings de la páginas web deben ser actualizados, un ordenador cuántico sería capaz de dar un sí o no de respuesta, exponencialmente más rápido que un ordenador tradicional.
![]()


autobus las palmas aeropuerto cetona de frambuesa