Actualidad informática
Noticias y novedades sobre informática
Nuevo software que resuelve CAPTCHA
CAPTCHA, el método para distinguir humanos de robots usando textos distorsionados, ha sido crackeado por la compañía Vicarious. Su objetivo, sin embargo, no es usar el software de forma maliciosa ni siquiera venderlo, sino avanzar en la senda de una verdadera inteligencia artificial.
En 1950, Alan Turing publicó un artículo en la revista Mind en el que se preguntaba ¿Pueden pensar las máquinas? Para resolver la pregunta sin ambigüedad, propuso el famoso test de Turing: un examinador hace preguntas a dos individuos que se hallan en otra habitación y se comunican por teletipo (el método ideal en tiempos de Turing, hoy sería simplemente internet). ¿Qué sucedería si una máquina tomara el papel de uno de ellos? ¿Sería capaz el examinador de descubrir a la máquina?
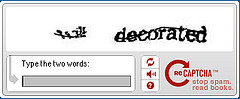
La forma más popular de distinguir humanos de robots es un algoritmo desarrollado en 2000 por la Carnegie Mellon University llamado CAPTCHA. Sus siglas significan Test de Turing público completamente automatizado para distinguir entre humanos y ordenadores. Más de 100.000 sitios web usan el algoritmo para distinguir la inteligencia basada en carbón (animal) de la basada en silíceo (ordenadores).
CAPTCHA presenta un conjunto de letras distorsionadas que un humano reconoce y un robot no (he de confesar que en múltiples ocasiones las letras presentadas me han resultado tan complicadas que me ha producido una notable irritación pasar de una secuencia fallida a otra). En 2009, Google presentó reCAPTCHA, una versión del algoritmo que además de su propósito original, es uno de los mayores esfuerzos de crowdsourcing que se están llevando a cabo. Se utiliza para descifrar palabras ilegibles de libros digitalizados. reCAPTCHA presenta dos palabras: una es conocida por el software y la otra es un texto digitalizado de un libro en papel que el sistema OCR (reconocimiento óptico de caracteres) ha sido incapaz de reconocer. Si el usuario acierta con la palabra conocida, el sistema asume que también lo ha hecho con la desconocida que se da por buena. De este modo, todos contribuimos al reconocimiento de textos en libros digitalizados.
CAPTCHA ha resultado sumamente útil. La única forma de romperlo de forma masiva en la actualidad es contratar empresas de mano de obra barata que usan a personas. Empresas con personal en Bangladesh que rompen siete CAPTCHAs por minuto a 50 céntimos la hora.
Para considerar CAPTCHA batido, basta con resolverlo un 1% de las veces. Ahora, una empresa llamada Vicarious dice ser capaz de resolverlo un 90% de las veces. Según la compañía, su intención no erar resolver CAPTCHA sino avanzar en una inteligencia artificial más parecida a la humana y la resolución de CAPTCHA es un simple subproducto. No pretenden usarlo de forma fraudulenta sino que es una demostración de cómo sus algoritmos emulan el funcionamiento del cerebro y de hecho, esto es solo una parte del camino de la emulación cerebral.
Vicarious dice que sus métodos son incluso más impresionantes que el aprendizaje que mostró el famoso IBM Watson. Ellos tratan de encontrar las matemáticas que subyacen a los procesos cerebrales. Vicarious ha recibido 15 millones de dólares de inversores como Dustin Moskovitz, cofundador de Facebook o el ex CEO de PayPal Peter Thiel.
El software de Vicarious: emula la visión humana en lo que ellos llaman redes corticales recursivas. Una capa de nodos detecta pixels. La siguiente capa detecta una agrupación específica de pixeles. La siguiente capa detecta una parte de una forma concreta. El proceso se repite hasta en ocho capas y usa más de ocho millones de nodos. Pusieron a trabajar el software para resolver un problema concreto y el resultado es que han resuelto CAPTCHA.
Fuente: ALT1040
Licencia CC
![]()

Test Público Completamente Automatizado para Diferenciar a los Seres Humanos de las Computadoras, Captcha
Las siglas inglesas de Completely Automated Public Turing Test to Tell Computer and Human Apart (Test Público Completamente Automatizado para Diferenciar a los Seres Humanos de las Computadoras) quizá os suenen más si las resumimos en el término más familiar Captcha.
Pero ¿qué utilidad tienen realmente estas palabras que aparecen en muchos sitios de Internet y quedebemos reproducir con nuestro teclado, en ocasiones forzando al máximo nuestra capacidad de lectura? (en mi caso, muchas veces me equivoco, lo cual me debe emparentar más con una computadora que con un humano).
Los Captcha llegaron para controlar el caos de spam generado en la década de 1990 en el ámbito de Internet. Los spambots inundaban los buzones de entrada del correo electrónico, y jalonaban los foros online. Pero todo esto cambió en el año 2000 gracias a un joven de 22 años.
Luis von Ahn, recien licenciado en la universidad, tuvo una idea para acabar con el spam: obligar a los que se inscribieran a probar que eran seres humanos y no un maldito bot. Así que buscó algo que resulta fácil para los seres humanos, pero no tanto a las máquinas: reconocer letras.
Se le ocurrió entonces presentar letras garabateadas y difíciles de leer durante el proceso de registro,y dejar solo unos segundos para descifrarlas y reproducirlas. Cuando Yahoo implementó este sistema, redujo los spambots de forma considerable en solo 24 horas.
A raíz del desarrollo de los Captcha, Von Ahn obtuvo un puesto como profesor de informática en la universidad Carnegie Mellon, así como contribuyó a que recibiera uno de los prestigiosos premios “genio” de la fundación MacArthur, dotado con medio millón de dólares. Sin embargo, algo fallaba aún.
El mayor error de los Captcha pasaba por exigir a los usuarios un montón de esfuerzo y tiempo colectivo para nada, o simplemente para evitar el spam. Un tiempo y un esfuerzo computacional humano que Von Ahn trató de darle utilizar inventando un sucesor de Captcha: ReCaptcha.
Con este nuevo sistema, la gente ya no teclea letras aleatorias, sino que teclea dos palabras procedentes de proyectos de escaneo de textos que el programa de reconocimiento óptico de caracteres de un ordenador no podría entender. La primera palabra sirve para confirmar lo que han introducido otros usuarios, y es que, por consiguiente, una señal de que el usuario es humano. La otra palabra es una palabra nueva que precisa de desambiguación.
Para garantizar que el sistema es efectivo, el sistema presenta la misma palabra borrosa a una media de 5 personas diferentes que la deben insertar correctamente antes de aceptarse como válida. Lo que ahorra mucho tiempo y dinero, tal y como explican Viktor Mayer-Schonberger y Kenneth Cukieen Big Data:
Con aproximadamente diez segundos por uso, 200 millones de ReCaptchas diarios ascienden a medio millón de horas diarias. El salario mínimo en Estados Unidos era de 7,25 dólares brutos por hora en 2012. Si uno tuviera que dirigirse al mercado para desambiguar las palabras que un ordenador no había conseguid descifrar, costaría alrededor de cuatro millones de dólares diarios, o más de mil millones de dólares al año.
Esta clase de trabajo colaborativo basado en el ingente número de datos que dejamos por nuestro paso por la Red es indudablemente la forma en la que muchos proyectos del presente y del futuro próximo están prosperando para mejorar nuestra calidad de vida o para afrontar problemas que de otro modo serían irresolubles. Como la web donde te predicen si tu vuelo se retrasará o se cancelará.
Fuente: Xataka CIENCIA
Licencia CC
![]()

autobus las palmas aeropuerto cetona de frambuesa