Actualidad informática
Noticias y novedades sobre informática
ProtonMail, correo criptografiado creado en el CERN

ProtonMail es la herramienta por excelencia para enviar correos encriptados de manera simple e intuitiva, creada en el lugar de nacimiento de internet, el CERN, con la colaboración de diferentes profesores de Cambridge, MIT y Harvard, ha logrado convertirse rápidamente en una increíble alternativa al servicio Lavabit, recientemente clausurado, esto se debe a su rápida viralización y algunas las entrevistas dadas por sus creadores.
Plantean que sólo el 2% de la población tiene conocimiento sobre este tipo de medidas y que realmente no es nada nuevo, de igual forma creen que en un futuro podrán mantener el servicio con cuentas premiun pero en esencia el envío de correos encriptados será totalmente gratuito.
![]()

Visita guiada al centro de computación del CERN
Allí se capturan y transfieren cientos de miles de gigabytes cada día en el Gran Colisionador de Hadrones; actualmente para hacerse una idea de la magnitud del asunto se capturan uno de cada 10 millones de eventos – una cantidad de información entrante que han cifrado en un petabyte por segundo, que pueden filtrar convenientemente para que sea más «digerible»
Fuente: microsiervos
![]()
El origen del error ‘404’
En el inicio de los tiempos, cuando Internet era un mundo extraño en la que todo se llevaba a cabo mediante consola y compartiendo archivos, un grupo de jóvenes científicos del CERN (Suiza) se dedicó a lanzar la World Wide Web, conocida mundialmente como “www”.
Ellos esperaban crear una infraestructura necesaria para tener acceso a contenido en varios formatos que estuviera en las computadoras conectadas a esta red y que combinara texto e imágenes.
Estos chicos empezaron a probar este protocolo dentro del mismo CERN, con la red de computadoras que había ahí mismo. Empezaron por usar la infraestructura del CERN para alojar a la naciente Internet.
En una habitación del cuarto piso (la habitación 404) les permitieron poner lo que sería la base central de la red, cualquier petición de ficheros por parte de un usuario era encaminada a esta oficina donde dos o tres personas se encargaban de localizar el archivo manualmente y mandarlo hasta el usuario que lo había solicitado. Todo a través de la red.
¿Pero qué pasaba cuando los chicos de la oficina 404 no podían encontrar el archivo o este no existía? Pues ellos se encargaban de mandar un mensaje que dijera “Room 404: file not found”.
Cuando el Internet se mundializó, el error 404 se siguió manteniendo y hasta nuestros días se puede ver cuando escribimos mal una dirección o cuando la página o archivo que buscamos en Internet ha sido borrado.
Fuente: CULTURIZANDO
![]()
El primer sitio web del mundo, bloqueado por una contraseña olvidada

El olvido de la contraseña de una antiguo ordenador está dificultando la labor de un equipo de científicos del Centro Europeo de Física de Partículas (CERN) que intenta reconstruir el primer sitio web de la historia y devolverlo a su dirección original.
«Internet y la web crean grandes cantidades de información, pero también la destruyen. Son medios poderosos, pero frágiles al mismo tiempo. El olvido de una simple contraseña provoca la pérdida de valiosa información», explicó en una entrevista a Efe Dan Noyes, jefe de ese equipo.
Corría el año 1989 y desde su computadora Next, en una pequeña oficina del CERN, el físico Tim Berners-Lee recurrió a internet -que ya existía- para desarrollar un sistema de intercambio de información entre científicos de diferentes universidades y laboratorios del mundo, que con el tiempo vendría a ser conocido como la web.
A través de ese sistema, se podían leer y publicar documentos, así como crear enlaces entre ellos.
En ese primer sitio web, hecho de distintas «páginas» en blanco y negro y «links» entre ellas en color azul, su creador explicaba cómo acceder a la web o a los documentos de otras personas, o la manera de configurar un servidor propio.
Cuatro años más tarde, el CERN publicó una declaración en la que autorizaba la utilización gratuita y libre de esta tecnología, una decisión crucial para su expansión y que fue el origen de la revolución de la información.
Durante el tiempo en que esta tecnología tuvo un uso exclusivamente académico, el primer sitio web fue cambiando al mismo tiempo que su creador editaba continuamente sus contenidos.
«No existe el primer sitio web porque se escribió sobre él. Existió durante un tiempo muy limitado, quizás unos meses, unos días o tal vez horas», dijo a Efe el editor del actual sitio web del CERN, Cian Micheal, quien trabaja en el equipo que pretende dar a conocer al mundo el primer prototipo de Berners-Lee, quien no había cumplido los 35 años cuando formuló su invención.
El proyecto de reconstrucción fue anunciado públicamente por el CERN con ocasión del vigésimo aniversario del libre acceso a la web.
La primera copia que se ha logrado reconstruir data de 1992 (http://info.cern.ch/hypertext/WWW/TheProject.html), pero en el CERN están seguros de la existencia de otra copia de 1991 localizada en el ordenador bloqueado de un profesor de la Universidad Chapel Hill en Carolina del Norte Paul Jones.
Jones conoció a Berners-Lee en una conferencia en San Antonio (EEUU) y se interesó tanto por el proyecto World Wide Web (WWW) que hizo una copia de los ficheros que la web contenía hasta aquel momento.
«Desafortunadamente, la computadora Next de Jones se encuentra bloqueada por una palabra de acceso que él mismo olvidó y expertos informáticos están actualmente intentando recuperar esa información», explicó Noyes.
Posteriormente, el disco duro con otra copia de una de las primeras versiones de la web fue robado o se extravío en un hotel -la verdad se desconoce- durante una presentación que Berners-Lee hizo del proyecto WWW a principios de los noventa en San Diego (EEUU).
La tarea por tanto no es fácil, pero Noyes cree que esta «abrumadora» búsqueda vale la pena porque hará que los usuarios se den cuenta de la fragilidad de la información virtual.
Contrariamente a una carta de amor con sobre y sello, un correo electrónico desaparecerá eternamente si se pierde una contraseña.
«Si personas famosas como Shakespeare hubiesen vivido en la era tecnológica, toda la información que conocemos de ellos por su correspondencia se habría perdido para siempre por no conocer una palabra de acceso», recalcó.
Internet, que nació en los años sesenta, es un sistema que permite la conexión entre distintas computadoras; mientras que la web es uno de sus principales servicios, que permite publicar y compartir documentos.
Fuente: lainformación.com
![]()
Primer sitio web cumple 20 años
La piedra fundamental de internet estaba en su protocolo de transferencia, y quien primero lo puso a prueba fue el propio CERN. Ayer, hace 20 años, nacía el primer sitio web de dominio público. Se trataba de la página del CERN, los mismos que hoy impulsan protones a velocidades incomprensibles, la que dio inicio a lo que hoy es la cara visible y pública de internet. Con Sir Tim Berners-Lee en el liderazgo, Internet comenzaba una revolución imparable. Como homenaje, el CERN quiere revivirla y ha comenzado un proyecto para hacerlo muy pronto.
El 30 de Abril de 1993 el CERN pasó a la historia como quien plantó la primera semilla que haría florecer a internet para que llegue a ser lo que es hoy. Agregándole un uso extra a internet más que como un protocolo para transferir archivos y recibir correo electrónico, la creación del software (NeXT) requerido para correr un servidor web gratuita y libremente, junto a un navegador y una librería inmensa de código, consiguió que internet se poblase.
En 1993 el primer sitio web de acceso público estaba hospedado en el ordenador NeXT de Berners-Lee y describía las características básicas de la WWW y cómo levantar servidores, configurar el navegador, etc. 20 años después, celebrando su aniversario, el CERN está comenzando un proyecto para restaurar el primer sitio web de la historia de acceso público.
Artículo completo en: TECNOLOGÍA AL INSTANTE
![]()
El CERN será de los primeros en usar la red de 100 Gbps de GEANT
El LHC genera alrededor de 30 Petabytes (un Petabyte = 1 000 000 Gigabytes) cada año por lo que necesita tener conexiones rápidas para poder distribuir los datos a los centros de análisis que colaboran con el CERN y que están repartidos por todo el mundo.
GEANT es la herramienta capaz de facilitar esta tarea. GEANT es la red europea para la comunidad investigadora y educativa. En ella participan las redes nacionales de investigación y educación (NREN) de Europa. Incluye instituciones con proyectos que van de la física de partículas al arte. Cuenta con más de 50000 km de conexiones y es usada por 40 millones de usuarios. Además proporciona uniones globales con otros centros de dato del resto del mundo.
El proyecto de GEANT es aumentar la velocidad hasta los 2 Tbps (terabits por segundo) en 2020 en toda Europa. El reto para el CERN es conectar el nuevo centro de cálculo a la red nacional húngara y por lo tanto a GEANT para conseguir que realmente Wigner sea una extensión del CERN.
Fuente: La Hora Cero
![]()
Scientific Linux y Ubuntu, los sistemas operativos empleados en el CERN
Una de las noticias más destacadas en este mes, ha sido el descubrimiento de una partícula compatible con la teoría de Higgs. Detrás del hallazgo de la mal denominada partícula de Dios, hay sistemas de cálculo muy sofisticados, animados por el sistema operativo GNU/Linux. En concreto, se han empleado Scientific Linux y Ubuntu en el descubrimiento.
Quiero mencionar cómo Linux (concretamente, Scientific Linux y Ubuntu) han tenido un papel fundamental en el descubrimiento de los bosones de nuevo en el CERN.
Los usamos cada día en nuestros análisis, junto con hosts de software abierto, como ROOT, y juegan un papel importante en el funcionamiento de nuestras redes de computadoras (Grid, etc.), utilizadas para el trabajo intensivo en nuestros cálculos.
Fuente: Reddit
![]()
20 aniversario de la primera foto subida a internet

En un evento organizado por el CERN para hacer promoción del recién inaugurado gran colisionador de hadrones, fue tomada la fotografía por Silvano de Gennaro, un científico que después de capturar el momento en el que las cantantes del grupo Les Horribles Cernettes posaban se sentó frente a su ordenador Macintosh, abrió Photoshop -primera versión de la aplicación- y comenzó con la edición. El 18 de julio se han cumplido 20 años.
Historia completa en: Motherboard
![]()
Preguntas y respuestas para entender (por fin) sobre el bosón de Higgs

1) ¿Qué es un bosón?
Los físicos clasifican las partículas del Universo en dos clases: bosones y fermiones. La partícula de Higgs tiene las propiedades que corresponden a los bosones, por eso se les llama así. En realidad, podría llamarse partícula de Higgs, pero todos lo conocen como bosón de Higgs.
2) ¿Qué hacen los bosones en la naturaleza?
Los bosones son las partículas que transmiten las fuerzas fundamentales del Universo. Las interacciones electromagnéticas (ondas de radio, rayos X, luz visible) se transmiten gracias a los fotones. Se cree que las fuerzas gravitatorias se transmiten por medio de un bosón llamado gravitón, que todavía no ha sido descubierto. Hay otros bosones que explican las fuerzas nuclear fuerte (gluones) y débil (bosones Z, W).
3) A mí me explicaron en el colegio que el átomo tenía protones, neutrones y electrones. ¿Dónde encaja el bosón de Higgs?
Durante el siglo XX, los físicos de partículas fueron más allá del modelo clásico del átomo (neutrones, protones, electrones) y descubrieron una gran cantidad de partículas subatómicas. El llamado Modelo Estándar intenta describir sus propiedades. Pero hay una pregunta que nunca se ha podido responder con claridad: ¿por qué las partículas tienen la masa que tienen? Peter Higgs postuló hace medio siglo que todo el Universo estaría inmerso en algo llamado campo de Higgs. Las partículas de Higgs (vale, los bosones de Higgs) serían los representantes de dicho campo, interactuando con las demás partículas y dotándolas de masa. Si el protón tiene más masa que el electrón, es porque interactúa con mayor fuerza con el campo de Higgs. De ahí la importancia de encontrar el bosón de Higgs y determinar sus propiedades. No se trata de una partícula más.
4) ¿Campo de Higgs? ¿Qué es eso?
Los físicos llaman campo a una región del espacio donde se manifiestan fuerzas. Hablamos de campo gravitatorio porque sentimos fuerzas debidas a la gravedad. Las fuerzas se transmiten por medio de bosones. El campo de Higgs está repleto de bosones de Higgs, que son los que actúan como mediadores entre el campo y el resto del Universo. Podemos imaginar que, si el agua de una piscina representa al campo de Higgs, los bosones de Higgs serían las moléculas que componen el agua.
5) ¿Cómo hace el bosón de Higgs para darle masa a las partículas?
Una partícula se moverá con mayor o menor facilidad según interactúe más o menos con los bosones de Higgs. Cuanto mayor será esa interacción, más difícil le resultará a una partícula atravesar el campo de Higgs y, por tanto, el efecto será que su masa será mayor. Para entenderlo, imaginemos que estamos en una gran sala con muchas personas, se está dando una fiesta y todos lo pasan bien. En un momento dado, Iniesta hace su entrada. Los asistentes a la fiesta le rodean, quieren hacerse una foto con él, le felicitan, le estrechan la mano, y todo eso hace que a Iniesta le cueste mucho llegar hasta la mesa con los canapés. A continuación, entra el típico pelmazo con el que nadie quiera hablar, al que llamaremos Mariano. Cuando lo ven entrar, la gente se aparta, hacen como que hablan unos con otros y le dan la espalda, nadie quiere “interactuar” con él, de forma que Mariano no encuentra impedimento para atravesar la sala. Así, las partículas de Higgs (las personas) que forman el campo (la sala) hacen que las partículas tipo Iniesta viajen lentamente, como si tuviesen una gran masa, mientras que las partículas del tipo Mariano atraviesan el espacio con facilidad, como si casi no tuviesen masa.
6) ¿Están seguros de que es el bosón de Higgs?
No del todo. Los científicos solamente pueden dar una probabilidad más o menos alta de éxito. Los bosones de Higgs se desintegran muy rápidamente, así que no pueden detectarse directamente. El procedimiento que se sigue en los grandes aceleradores de partículas como el LHC consiste en hacer chocar entre sí dos partículas, con la suficiente energía para que pueda formarse un bosón de Higgs. El bosón, a su vez, se desintegrará, y los productos de la desintegración son los que se detectan en los experimentos. Es algo así como destrozar dos relojes haciendo que choquen entre ellos, examinar los trozos que quedan, y a partir de ellos deducir cómo funciona un reloj. El reciente anuncio eleva la probabilidad de haber descubierto el bosón de Higgs al 99.99995% lo que en la comunidad científica se considera certeza. Además de ello, queda la tarea de identificarlo más allá de cualquier duda razonable. Puede tratarse del bosón de Higgs, de un bosón de Higgs (puede que haya varios) o de otro tipo de partículas. Siempre hay que estar abierto a otras posibilidades. Por el momento, todo apunta a que se trata realmente del bosón de Higgs, pero los científicos son cautos y estudiarán sus propiedades a fondo durante los próximos años.
7) ¿Por qué ha costado tanto encontrar el bosón de Higgs?
Fundamentalmente, por su masa. Un bosón de Higgs pesa más que un centenar de átomos de hidrógeno. El Universo creó el campo de Higgs durante la gigantesca explosión de energía que conocemos como Big Bang. Para poder reproducir esas condiciones, debemos usar partículas con una gran energía, y el modo de obtenerlas es mediante grandes aceleradores. El mayor de todos ellos es el LHC (Large Hadron Collider), un enorme acelerador perteneciente al CERN (Consejo Europeo de Investigación Nuclear), y han hecho falta décadas de preparación y un gran esfuerzo técnico y financiero.
8) ¿Para qué sirve gastar tanto dinero en una partícula? ¡Que estamos en crisis!
Descubrimientos como el del bosón de Higgs ayudarán a entender el funcionamiento del Universo. Buscar aplicaciones del bosón de Higgs en procesos industriales es ciencia-ficción en estos momentos, pero no olvidemos que la electrónica moderna está basada en fenómenos de mecánica cuántica y relatividad descubiertos a comienzos del siglo XX, y que entonces tampoco tenían aplicación práctica inmediata. Faraday, cuya ley de inducción nos permite ahora crear electricidad, dijo en 1850 al ministro de finanzas británico: “no sé qué aplicación tiene mi descubrimiento, pero sí sé una cosa, y es que un día usted cobrará impuestos por ello.”
No hace falta irse tan lejos en el futuro. El dinero invertido en el CERN no se limita a desaparecer sin más. Las empresas que participan en la construcción de las instalaciones del CERN desarrollan nuevas tecnologías y procesos de fabricación, que luego tienen aplicaciones industriales muy diversas. Los científicos y técnicos españoles reciben allí una preparación sin igual en el mundo. Ni siquiera los norteamericanos pueden igualarles en este punto, ya que EEUU renunció hace años a construir un acelerador como el LHC por motivos presupuestarios.
La propia Internet tal y como hoy la conocemos, con sus hipervínculos y sus páginas web, fue inventada en el CERN hace veinte años. Su propósito era tan sólo ayudar a los científicos del centro a gestionar los datos que generaban los experimentos, algo sin mayor trascendencia en ese momento. Dos décadas después, la economía de Internet genera anualmente una riqueza económica mayor que la que jamás se ha invertido en toda la historia del CERN. La nueva red de comunicaciones que se está creando actualmente para gestionar los datos de grandes proyectos científicos como el LHC se convertirá en la Internet 2 del mañana.
9) Por fin apareció el bosón de Higgs. ¿Significa eso que el LHC ya no sirve para nada?
¡En absoluto! El LHC apenas acaba de saltar al terreno de juego. Ni siquiera ha sido usado a potencia máxima todavía. Se trata de uno de los instrumentos científicos más grandes y complejos de la historia, y dará muchas más información en los años venideros. Hay todavía muchas preguntas fundamentales sin resolver. Por ejemplo, ¿cuál es la masa del neutrino? ¿Dónde esta el gravitón, que sirve para explicar la fuerza de la gravedad? En la actualidad el 95% del Universo está hecho de algo llamado “materia oscura,” que es la forma elegante de los científicos para decir “no sabemos de qué esta hecho esto.” ¿Cuál es la composición de esa misteriosa materia oscura? Experimentos como los del LHC pueden ayudar a darnos respuestas.
10) Pues al señor Higgs le estarán preparando ya el premio Nobel, ¿no?
Lo cierto es que no se sabe bien. En el descubrimiento del bosón de Higgs han participado miles de científicos durante décadas de duro trabajo. Resultaría muy complicado ponerlos a todos en un pedestal, y la academia Nobel no permite dar premios a un trabajo colectivo. Pero sí, en el caso de que se otorgue un premio Nobel por este descubrimiento, Peter Higgs estará de los primeros en la lista.
11) ¿Por qué llaman al bosón de Higgs “la partícula de Dios”?
El apelativo proviene de un libro de texto sobre física de partículas escrito en los años noventa, en el que se describía al bosón de Higgs como “la partícula puñetera” (the goddamn particle). El editor, por su cuenta y riesgo, decidió cambiarle el nombre a “la partícula de Dios” (the God particle). Es un nombre pegadizo, y define bien la importancia que tiene en cuanto que partícula creadora de masa. Pero tenga por seguro que la comunidad científica odia ese nombre con todas sus fuerzas. Ojalá los periodistas dejen de utilizarlo.
12) ¿Y si no hubieran encontrado el bosón de Higgs?
En ese caso, el Modelo Estándar tendría que ser modificado, o sustituido por otro. Puede que tengamos que hacerlo, si el LHC descubre nuevas partículas o fenómenos que los científicos no habían considerado. Por eso la ciencia tiene que observar y experimentar: no se encuentra si no se busca.
Fuente: Física de Película
Bajo licencia Creative Commons
![]()
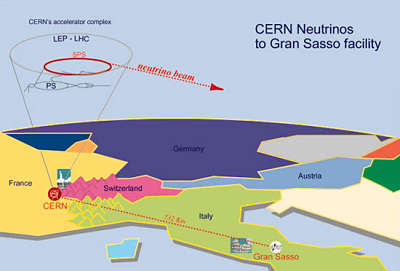
Una mala conexión dio lugar a «neutrinos más rápidos que la luz»
Parece que los resultados de neutrinos más rápidos que la luz, que se anunció en septiembre pasado por la colaboración ÓPERA en Italia, se debió a un error después de todo. Una mala conexión entre una unidad de GPS y un ordenador puede ser el culpable.
Los físicos habían detectado neutrinos que viajan desde el laboratorio del CERN en Ginebra, al laboratorio del Gran Sasso cerca de L’Aquila, que parecía que hacían el viaje en unos 60 nanosegundos menos que la velocidad de la luz. Muchos otros físicos sospecharon que el resultado se debió a algún tipo de error, dado que parece en desacuerdo con la teoría especial de la relatividad de Einstein, que dice que nada puede viajar más rápido que la velocidad de la luz. Esta teoría ha sido reivindicado por muchos experimentos durante décadas.
De acuerdo a fuentes familiarizadas con el experimento, la diferenciade 60 nanosegundos parece provenir de una mala conexión entre el cable de fibra óptica que conecta el receptor GPS utilizado para corregir el tiempo de vuelo de los neutrinos y una tarjeta electrónica en un ordenador. Después de apretar la conexión y midiendo el tiempo que tardan los datos en recorrer la longitud de la fibra, los investigadores encontraron que los datos llegan 60 nanosegundos antes de lo que supone. Desde este momento se resta del tiempo total de vuelo, lo que parece explicar la llegada temprana de los neutrinos. Nuevos datos, sin embargo, serán necesarios para confirmar esta hipótesis.
![]()

autobus las palmas aeropuerto cetona de frambuesa