Actualidad informática
Noticias y novedades sobre informática
El CERN será de los primeros en usar la red de 100 Gbps de GEANT
El LHC genera alrededor de 30 Petabytes (un Petabyte = 1 000 000 Gigabytes) cada año por lo que necesita tener conexiones rápidas para poder distribuir los datos a los centros de análisis que colaboran con el CERN y que están repartidos por todo el mundo.
GEANT es la herramienta capaz de facilitar esta tarea. GEANT es la red europea para la comunidad investigadora y educativa. En ella participan las redes nacionales de investigación y educación (NREN) de Europa. Incluye instituciones con proyectos que van de la física de partículas al arte. Cuenta con más de 50000 km de conexiones y es usada por 40 millones de usuarios. Además proporciona uniones globales con otros centros de dato del resto del mundo.
El proyecto de GEANT es aumentar la velocidad hasta los 2 Tbps (terabits por segundo) en 2020 en toda Europa. El reto para el CERN es conectar el nuevo centro de cálculo a la red nacional húngara y por lo tanto a GEANT para conseguir que realmente Wigner sea una extensión del CERN.
Fuente: La Hora Cero
![]()

El software del colisionador de partículas (LHC)
Por primera vez se han dado en el LHC colisiones a 7 TeV. En el instante en que sus detectores registran sucesos relacionados con una colisión, los desafíos se mueven desde el reino del hardware y el software, ya que el LHC producirá, literalmente, más datos de lo que podemos manejar. Tenemos que averiguar a lo que aferrarse en tiempo real, y enviarlo a todo el mundo a través de conexiones dedicadas a 10 GBp/s; y la necesidad por parte del extremo receptor de guardarlo de forma segura y llevar a cabo el tipo de análisis que se espera revele una nueva física. Vamos a proporcionar una breve visión a los temas de cómputo creado por el LHC.
Encontrar lo que estamos interesados
El LHC no es sólo excepcional en términos de la energía que puede alcanzar, sino que tiene una muy alta luminosidad, lo que significa que produce colisiones a una velocidad asombrosa. Howard Gordon indicó que las interacciones se llevarán a cabo a un ritmo de 600 millones de eventos por segundo para cada detector. Incluso si tuviéramos la capacidad de guardar los comprobantes de todos ellos (que no), muchos representarían a la física conocida. Srini Rajagopalan, un empleado de Brookhaven que trabaja en el CERN, dijo que de los millones de colisiones que ocurren cada segundo, estaremos almacenando aproximadamente 400 de ellas.![]()
Obviamente, este proceso es un sacrificio muy importante, complicado por el hecho de que estamos esperando para ver las partículas que han sido predichas por las diferentes teorías (lo ideal, nos gustaría también detectar cosas que los teóricos no esperaban). ¿Cómo funciona esto? Un indicio se proporcionó cuando a Stephanie Majewski se le preguntó sobre un modelo para la existencia de dimensiones más allá de nuestro bien conocido universo de cuatro. «Las dimensiones extra nos darán un montón de muones», dijo Majewski, «no podía faltar.» En resumen, la mayoría de cosas que estamos esperando o la esperanza de encontrarlas son el producto de algunas predicciones bastante específicas, y producirán patrones igualmente predecibles de partículas en los detectores (Chris Lee cubrió esto en detalle un poco más).
Rajagopalan describe cómo el software del detector ATLAS, incluyó lo que llamó «filtros de eventos». Básicamente, el software puede determinar el grado en que las partículas y la energía que sale de una colisión coinciden con un patrón que es de esperar que al ser producido por una partícula dada. Estas expectativas pueden basarse tanto en lo que ya hemos visto en partículas conocidas como el quark top, o lo que predice la teoría.
En este momento, el software cuenta con 300 filtros de eventos, pero aparentemente puede manejar hasta 8000, y dar prioridad a cada una de ellos, entonces, por ejemplo, es probable que trate de capturar eventos de más potencial Higgs que los quarks arriba (top).
Estos filtros pueden tener diversos grados de restricciones, lo que significa que se pueden establecer para capturar eventos que son similares a, pero que no se ajustan exactamente a las predicciones. También es posible detectar la superposición parcial entre eventos. Así, por ejemplo, una partícula desconocida podría producir un conjunto de familias como parte de su decaimiento, incluso si no hay un filtro específico para las partículas, el evento puede ser capturado porque se ve un poco como algo que también se desintegra a través de un conjunto similar de partículas.
Esto último es importante en caso de que los teóricos empezaran a proponer ideas mucho después de que el LHC hubiera comenzado la recolección de datos. Cuando Howard Gordon planteó esto, es posible tomar nuevas ideas y compararlas con los modelos existentes para identificar los posibles lugares de solapamiento, y para ir desde allí a los datos primarios y probar contra las predicciones en detalle.
La física computacional
En la interfaz principal de ATLAS para EE.UU., el principal papel de Brookhaven será simplemente almacenar cualquier dato que llegue del evento a través de filtros a medida, y su distribución a diferentes (Tier 2 y 3) lugares de todo el país (Brookhaven también cuenta con una red de 10000 núcleos que llevará a cabo un análisis). Como lo describió Ofer Rind, ya que cada caso es esencialmente independiente, todos ellos se pueden analizar por separado, es un problema «paralelo», en términos de informática.
Como resultado, la comunidad de «física de altas energías» tiene una gran experiencia con la informática en red (grid). «Hemos estado haciendo esto por un tiempo, y con mucho menos dinero», dijo Rind.
Parte de esa potencia de cálculo, simplemente va a convertir los datos en bruto a las identidades de las partículas y las pistas, y otra parte a modelar lo que podría ser similar a una partícula teórica. Pero, a medida que más datos estén disponibles, muchos de los cálculos implican simplemente escanear eventos para determinar qué tanto o ninguno de ellos coincide con las predicciones teóricas. Los usuarios de la red serán capaces de especificar un programa de análisis (entre ellos uno que envíe la tarea), de identificar los datos que deben procesarse, y simplemente establecer el trabajo sobre la marcha. Sobre la base de la prioridad del trabajo, la red usará más tiempo de procesador de repuesto, y luego procesará el software y los datos juntos en las mismas máquinas, lo que permite el análisis a realizar.
En un futuro próximo, este tipo de programas deben comenzar a construir un catálogo de las colisiones que tienen el número correcto, propiedades de correctas de los muones, fotones de la energía correcta, etc, para contener una indicación de algo que es nuevo para la física. Y, una vez se identifican una señal de ruido fuera de la estadística, entonces se podría estar listo para iniciar la actualización del modelo estándar (y, posiblemente, todos de la cosmología).
Fuente: arstechnica
![]()
¿El LHC revolucionará también Internet?
Ya sabemos que el Gran Colisionador de Hadrones (LHC por sus siglas en inglés Large Hadron Collider) será el experimento físico mayor y más caro jamás realizado por la humanidad. Colisionar partículas relativistas a energías antes inimaginables (hasta 14 TeV a finales de la década) generará millones de partículas (conocidas y sin descubrir todavía) de cuyo seguimiento y caracterización deberán encargarse enormes detectores de partículas. Este experimento histórico requerirá una esfuerzo masivo de recogida y almacenaje de información, reescribiendo las reglas del manejo de información. Cada cinco segundos, las colisiones del LHC generarán el equivalente a un DVD de información, o sea un ritmo de producción de datos de un gigabyte por segundo. Para verlo en perspectiva, un ordenador doméstico corriente con una conexión muy buena podría bajar datos a un ritmo de uno o dos megabytes por segundo (¡con mucha suerte! a mí me bajan a 500 kilobytes/segundo). De manera que los ingenieros del LHC han diseñado un nuevo tipo de método para manejar información que puede almacenar y distribuir petabytes (un millón de gigabytes) de información a los colaboradores del LHC de todo el mundo (sin que envejezcan ni les salgan canas mientras esperan que termine la descarga).
En 1990, la Organización Europea para Investigación Nuclear (CERN) revolucionó la forma en que vivimos. El año anterior, Tim Berners-Lee, un físico del CERN, escribió una propuesta para la gestión de información electrónica. Adelantó la idea de que la información podría ser transferida fácilmente por Internet utilizando algo llamado «hipertexto». Con el tiempo, Berners-Lee y su colaborador Robert Cailliau, ingeniero de sistemas también del CERN, ensamblaron una única red de información para ayudar a que los científicos del CERN colaboraran y compartieran información desde sus ordenadores personales sin tener que guardarla en voluminosos dispositivos de almacenaje. El hipertexto permitió a los usuarios navegar y compartir textos mediante páginas web utilizando hiperenlaces. A continuación, Berners-Lee creó un navegador-editor y pronto se dio cuenta de que esta nueva forma de comunicación podía ser compartida por una gran cantidad de personas. El CERN fue el responsable del primer sitio web del mundo: http://info.cern.ch/ y se puede ver un ejemplo del aspecto que tenía ese sitio en el sitio web del World Wide Web Consortium
De manera que el CERN no es extraño a la gestión de información por Internet, pero el novísimo LHC requerirá un tratamiento especial. Tal como pone de manifiesto David Bader, director ejecutivo de computación de alto rendimiento del Georgia Institute of Technology, el ancho de banda actual que permite Internet es un enorme cuello de botella, que hace más deseables otras formas de compartir información. «Si miro el LHC y lo que está haciendo para el futuro, la única cosa que la Web no ha podido hacer es gestionar una cantidad fenomenal de datos» declaró, en el sentido de que es más fácil grabar grandes bloques de información en discos duros de terabytes y enviarlos por correo a los colaboradores. Aunque el CERN previó la naturaleza colaborativa de compartir datos en la World Wide Web, la información que generará el LHC desbordará fácilmente los pequeños anchos de banda disponibles actualmente.
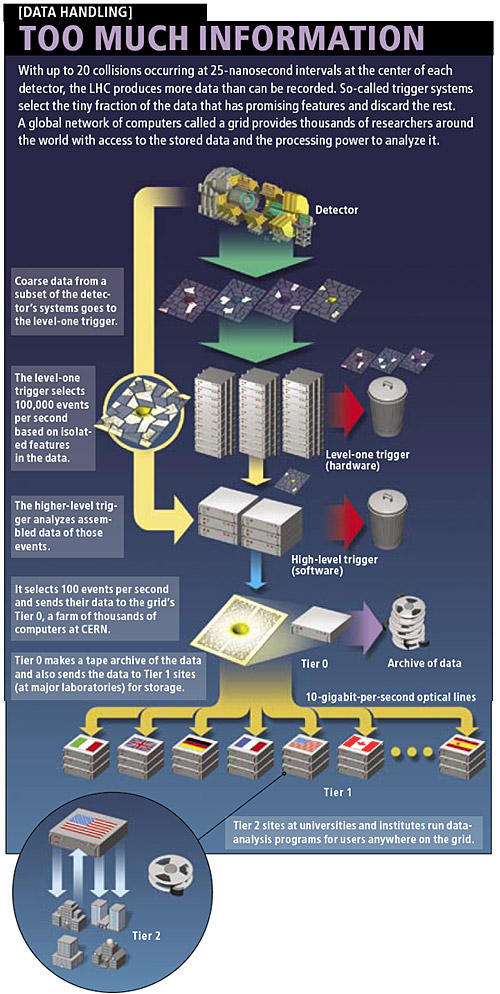 |
| Cómo funciona el cómputo en red del LHC (CERN/Scientific American)© Crédito imagen: CERN/Scientific American (pulsar sobre la imagen para ampliarla) |
Ésta es la razón de que fuera diseñado el programa de Cómputo en Red del LHC. El programa gestiona la producción de vastos conjuntos de datos en niveles, el primero de los cuales (Nivel 0) está situado en las instalaciones del CERN cerca de Ginebra, en Suiza. El Nivel 0 consiste en una enorme red paralela de computación que contiene 100.000 CPUs avanzados que han sido preparados para almacenar y gestionar de inmediato los datos en bruto (1s y 0s del código binario) originados por el LHC. En este punto es preciso resaltar que los sensores no detectarán todas las colisiones de partículas, sino que sólo se puede capturar una fracción muy pequeña. Aunque sólo se pueda detectar un número comparativamente pequeño de partículas, sigue representando una cantidad ingente de información.
El Nivel 0 gestiona porciones de los datos obtenidos propulsándolos, mediante líneas específicas de fibra óptica de 10 gigabits-por-segundo, hacia 11 puntos de Nivel 1 situados en Norteamérica, Asia y Europa. Esto permite a colaboradores como el Relativistic Heavy Ion Collider (RHIC) del Brookhaven National Laboratory de Nueva York analizar datos del experimento ALICE, comparando los resultados de las colisiones de iones de plomo del LHC con sus propios resultados de colisiones de iones pesados.
Desde los ordenadores internacionales de Nivel 1, los bloques de datos son ensamblados y reenviados a 140 redes de ordenadores de Nivel 2 situadas en universidades, laboratorios y empresas privadas de todo el mundo. Es en este punto donde los científicos tendrán acceso a los bloques de datos para realizar la conversión desde el código binario bruto a información utilizable sobre energías y trayectorias de partículas.
El sistema de niveles está muy bien, pero no funcionaría sin un tipo de software altamente eficiente llamado «middleware» («software intermedio»). Al intentar acceder a los datos, el usuario puede querer información que está repartida en los petabytes de datos de diferentes servidores en distintos formatos. Una plataforma de middleware de código abierto llamada Globus tendrá la enorme responsabilidad de reunir la información requerida en forma continua, como si esa información ya estuviera archivada en el ordenador del investigador.
Es esta combinación del sistema de niveles, conexión rápida y software ingenioso lo que podrá expandirse más allá del proyecto LHC. En un mundo en el que todo tiene que ser «inmediatamente», este tipo de tecnología podría hacer Internet transparente para el usuario final. Habría acceso instantáneo a todo, desde información producida por experimentos en el otro lado del mundo hasta visionar películas en alta definición si tener que esperar a que termine la descarga. De forma parecida al invento del HTML por parte de Berners-Lee, el cómputo en red del LHC podría revolucionar la manera en que utilizamos Internet.
Crédito de las imágenes: CERN / Scientific American
Traducido del inglés para Astroseti.org por Marisa Raich

autobus las palmas aeropuerto cetona de frambuesa